
From standard ML metrics to production
How often do you test ML models in a Jupyter notebook, get good results, but still cannot convince your boss that the model should be used right away?
Or maybe you manage to convince her and put the model in production, but you do not see any impact on business metrics?
Luckily for you, there are better ways to test ML models in the real world and to convince everyone (including you) that they add value to the business.
In this article you will learn what these evaluation methods are, how to implement them, and when should you use each.
The problem with standard ML evaluation metrics
We, data scientists and ML engineers, develop and test ML models in our local development environment, for example, a Jupyter notebook.
We use standard ML evaluation metrics depending on the kind of problem we are trying to solve:
- If it is a regression problem we print things like mean squared errors, Huber losses, etc.
- If it is a classification problem we print confusion matrices, accuracies, precision, recall, etc.
We split the data into a train and a test set, where the first is used to train the model (ie find the model parameters), and the latter is used to evaluate its performance. The train and test sets are disjoint to guarantee our evaluation metrics are not biased and overly optimistic.
The problem is that these numbers have almost no meaning for non-ML folks around us, including the ones who eventually call the shots and prioritize what pieces of software make it into production, including our ML models.
In other words, this is not the best way to test ML models and convince others they work.
Why is so?
Because of 2 reasons:
- These metrics are not business metrics, but rather abstract.
- There is no guarantee that once deployed your ML will work as expected according to your standard metrics because many things can go wrong in production.
Ultimately, to test ML models you need to run them in production and monitor their performance. However, it is far from optimal to follow a strategy where models are directly moved from a Jupyter notebook to production.
This principle applies to any piece of software, but it is especially important for ML models, due to their extreme fragility.
The question is then, how can we safely walk the path from local standard metrics to production?
There are at least 3 things you can do before jumping straight into production:
- Backtesting your model
- Shadow deploying your model
- A/B testing your model
They represent incremental steps towards a proper evaluation of the model and can help you and the team safely deploy ML models and add incremental value to the business.
Let’s see how these evaluation methods work, with an example.
Method 1: Backtesting your ML Model
Backtesting is an inexpensive way to evaluate your ML model, that you can implement in your development environment.
Why inexpensive?
Because
- You only use historical data, so you do not need more data than what you already have.
- You do not need to go through a deployment process, with can take time and several iterations to get right.
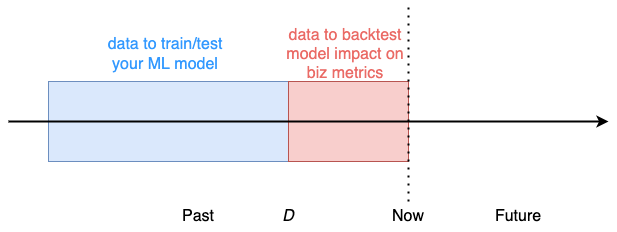
The idea behind backtesting is very simple:
You pick a date D in the past, that serves as a cutoff between the data you use to train/test your ML model, and the data you use to estimate the hypothetical impact the model would have had on business metrics if it had been used to take actions.
For example, imagine you work in a financial trading firm as an ML developer.
The firm manages a portfolio of investments in different assets (stocks, bonds, crypto, commodities…). Given the tons of price data for all these assets, you think you can build an ML model that can decently predict price changes, i.e. whether the price of each asset will go up or down the next day.
Using this predictive ML model, the firm could adjust its portfolio positions and ultimately improve its profitability.
The model you wanna build is essentially a 3-class classifier, where
- the target is
upif the next day’s price is higher than today’s,sameif it stays the same (or very close), anddownif it goes down. - The features are static variables, like asset type, and behavioral, like historical volatilities, price trends, and correlations in the last N days.
You develop the model in your local environment and you print standard classification metrics, for example, accuracy.
For the sake of simplicity, let’s assume the 3 classes are perfectly balanced in your test set, meaning 33.333% for each of the classes up, same, down.
And your test accuracy is 34%.
Predicting financial market movements is extremely hard, and our model accuracy is above the 33% baseline accuracy you get if you always predict the same class.
Things look very promising, and we tell our manager that we should start using the model right away.
Our manager, a non-ML person who has been in this industry for a while, looks at the number and asks:
“Are you sure the model works? Will it make more money than the current strategies?”
This is probably not the answer you expected, but sadly for you, it is one of the most common ones. When you show such metrics to non-ML people who call the shots in the company, you will often get a NO. Hence, you need to go one step further, to prove your model will generate more profit.
And you can do this with a backtest.
You pick the cutoff date D, for example, 2 weeks ago, and
- Train your ML classifier using data up to day D.
- Compute the daily profit and loss we would have had on the portfolio from day D until today if we had used the model predictions to decide whether to buy, hold, or sell each of our positions.
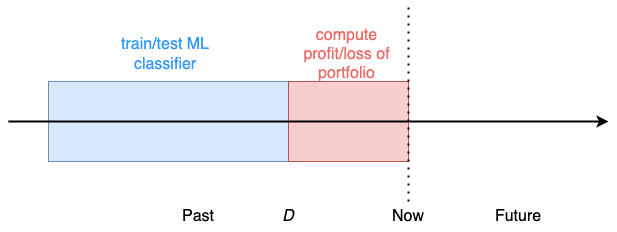
If your backtest shows negative results, meaning your portfolio would have generated a loss, you go back to square 1. On the contrary, if the profit of the portfolio in the backtest period is positive, you go back to your manager:
“The backtest showed a positive result, let’s start using the model”
To which she answers
“Let’s go step by step. Let’s first deploy it and make sure it actually works in our production environment.”
This leads to our next evaluation step.
Method 2: Shadow deployment in production
ML models are very fragile to small differences between the data used to train them and the data sent to the model at inference time.
For example, if you have a feature in your model that:
- had almost no missing values in your training data, but
- is almost always unavailable (and hence missing) at inference time
Your model performance at inference time will deteriorate, and be worse than what you expected. In other words, both the standard evaluation metrics and the backtesting results are almost always an upper bound of the true performance of the model.
Hence, you need to take one step further and test the model when it is actually used in production.
A safe way to do so is using a shadow deployment, where the model is deployed and used to predict (in this case asset price changes) but its output is NOT used to take actions (i.e. rebalance the portfolio).
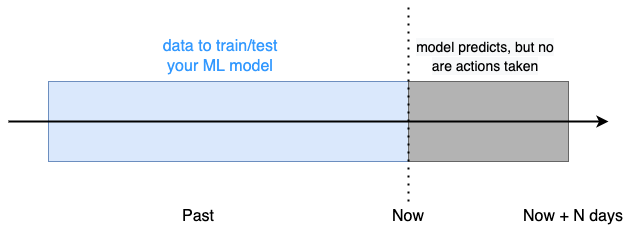
After N days, we look at the model predictions, and how the portfolio profit would have been if we had used the model to take action.
If the hypothetical performance is negative (i.e. a loss) we need to go back to our model and try to understand what is going wrong, e.g.
- was the data sent to the model very different from the one in the training data? Like missing parameters? Or different categorial features?
- was the backtest period a very calm and predictable one, while today’s market conditions are very different?
- is there a bug in the backtest we ran previously?
- …
If the hypothetical profit is positive, we get another sign our model is working. So you go back to your boss on Friday and say:
“The model would have generated profit this week if we had been using it. Let’s start using it, come on”.
To which she replies,
“Didn’t you see this week’s performance of our portfolio? It was incredibly good. Was your model even better or worse?”
You spent the whole week so focused on your live test, that you even forgot to check the actual performance.
Now, you look at the two numbers:
- the actual portfolio performance of the week
- and the hypothetical performance for your model
and you conclude that your number is slightly above the actual performance. This is great news for you! So you rush back to your manager and tell her the good news.
This is what she responds:
“Let’s run an A/B test next week to make sure this ML model is better than what we have right now”
You are now on the verge to explode. So you ask:
“What else do you need to see to believe this ML model is better?”
And she says:
“Actual money”
You call it a week and take well-deserved 2-day rest.
Method 3: A/B testing your model
So far, all our evaluations have been either
- too abstract, like the
34%accuracy - or hypothetical. Both the backtesting and the shadow deployment produced no actual money. We estimated the profit instead.
We need to compare actual dollars versus actual dollars, to decide if we should use our new ML-based strategy instead. This is the final way to test ML models, that no one could refute.
And to do so we decide to run an A/B test from Monday to Friday.
Next Monday we randomly split the portfolio of assets into:
- a control group (A), e.g. 90% in terms of market value
- a test group (B), e.g. remaining 10% in terms of market value
Control group A will be rebalanced according to the current strategy used by the company. Test group B will be rebalanced using our ML-based strategy.
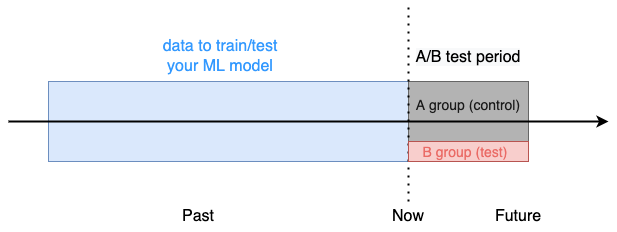
Every day we monitor the actual profit of each of the 2 sub-portfolios and on Friday we stop the test.
When we compare the aggregate profit of our ML-based system vs the status quo, 3 things might happen. Either
- the status quo performed much better than your ML system. In this case, you will have a hard time convincing your manager that your strategy should stay alive.
- both sub-portfolios performed very similarly, which might lead your manager to extend the test for another week to see any significant differences.
- or, your ML system significantly overperformed the status quo. In this case, you have everything on your side to convince everyone in the company that your model works better than the status quo, and should at least be used for 10% of the total assets, if not more. In this case, a prudent approach would be to progressively increase the percentage of assets managed under this ML-based strategy, monitoring performance week by week.
After 3 long weeks of ups and downs, you finally get an evaluation metric that can convince everyone (including you) that your model adds value to the business.
Wrapping it up
Next time you find it hard to convince people around you that your ML models work, remember the 3 strategies you can use to test ML models, from less to more convincing,
- Backtesting
- Shadow deployment in production
- A/B testing
The path from ML development to production can be rocky and discouraging, especially in smaller companies and startups that do not have reliable A/B testing systems in place.
It is sometimes tedious to test ML models, but it is worth the hassle.
Believe me, if you use real-world evaluation metrics to test ML models, you will succeed.
Let’s connect!
Wanna learn more about real-world Data Science and Machine Learning? Subscribe to my newsletter, and connect on Twitter and LinkedIn 👇🏽👇🏽👇🏽