
Ready to build your first agent using parametric q learning?
Credits for this beautiful picture go to Yogendra Singh ❤️
Welcome to my reinforcement learning course ❤️
This is part 4 of the Hands-on Course on Reinforcement Learning, which takes you from zero to HERO 🦸♂️.
- Introduction to Reinforcement Learning
- Tabular Q-learning
- Tabular SARSA
- Parameteric Q learning (today)
Sorry that I’ve kept you waiting longer for this sequel, I wanted to share the whole learning process with you, so you know that good results don’t always come easy. But once they do – they are worth the trouble️.
Today we are entering new territory….
A territory where Reinforcement Learning meets the optimization techniques that are essential in modern Machine Learning. A killer combo to solve tons of different problems and environments 🚀.
The problem we will work on is the famous Cart Pole balancing, where the goal is to balance a pole attached to a cart, by moving the cart left and right.
This is what the Deep Q-Agent we will implement at the end of this adventure looks like:
The techniques we will explore in this part are the backbone behind the impressive achievements in the field of Reinforcement Learning in the last 5 to 10 years.
There is a lot of stuff to digest, so we are going to split the workload into 3 parts:
- In part 4 (this one!) we implement a Linear Q agent to get an okay-ish solution.
- Then, in part 5 we add depth and implement a Deep Q agent to get a good solution.
- Finally, in part 6 we will see how to fine-tune all the hyper-parameters to maximize performance. Here we finally get the awesome Deep Q agent you saw above!
In each part, we will throw in new ideas, tricks, and implementation details you need to master. More importantly, I want you to get used to failing when building RL solutions. Because this is what happens most of the time.
Advanced RL techniques, like the ones we will see in these 3 parts, are very powerful but require careful implementation and hyper-parameter tuning.
Debugging RL algorithms is not an easy task, and the only way to become better at it is by making mistakes. One of my biggest frustrations, when I started learning Reinforcement Learning, was the apparent simplicity of the algorithms, and the extreme difficulty when trying to replicate published results.
Reinforcement Learning is hard by itself, so let’s try not to overcomplicate it even more. Let’s go step by step!
All the code for this lesson is in this Github repo. Git clone it to follow along with today’s problem
And don’t forget to give it a ⭐!

Part 4
1. The Cart Pole problem 🕹️
A pole is attached to a cart with an un-actuated joint. And your goal is to move the cart position, left and right, to prevent the pole from falling.
We will use the implementation of the CartPole-v1 you can find in the OpenAI Gym.
Why this problem?
So far in the course, we have used classical Reinforcement Learning algorithms, Q-learning (part 2), and SARSA (part 3) in a discrete/tabular environment.
Today’s problem is slightly more complex because its state space is too large to be discretized. Instead, we need to level up our game and use more powerful RL algorithms.
We will use parametric Q-learning, a technique that combines the classic Q-learning we saw in part 2, with parametric approximations, either linear ones (here in part 4) or a more complex one like neural nets (in part 5).
Parametric Q-learning using neural nets (aka Deep Q-learning) lies behind many recent breakthroughs in Reinforcement Learning, like the famous Atari game player by DeepMind.
Let’s get familiar with the specifics of this environment!
2. Environment, actions, states, rewards
👉🏽 notebooks/00_environment.ipynb
The state is represented by 4 numbers:
- The cart position x from -2.4 to 2.4.
- The cart velocity v
- The pole angle θ with respect to the vertical from -12 to 12 degrees (from -0.21 to 0.21 in radians)
- The pole angular velocity ω. This is the rate of change of θ.
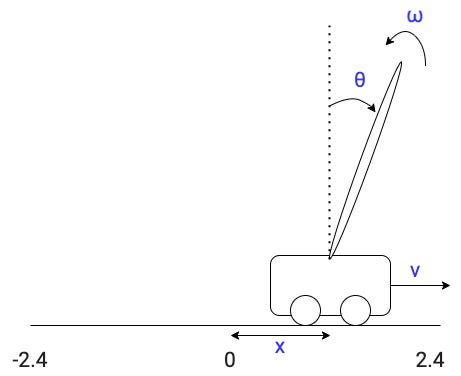
An episode terminates when either:
- the cart goes beyond the limits: x > 2.4 or x < -2.4
- the pole is too far from the vertical: θ > 12 degrees or θ < -12 degrees.
- or we reached the maximum number of episodes steps, 500. In this case, the agent perfectly solved the episode.
Each starting state component is sampled randomly from the interval [-0.05, 0.05]. Sometimes, the starting position is so close to balance that the episode is easy. Other times, the starting position is so off-balance that the episode is much harder to solve, and sometimes even impossible.
What about the cart velocity v and the pole angular velocity ω. Are these values bounded too?
First, let’s load the CartPole-v1 environment.

If you look at the OpenAI gym interval variables
env.observation_space.lowenv.observation_space.high
you will see that these 2 numbers seem to be arbitrarily large or small.

In practice, this is not true. Both v and ω have narrower intervals, but this is something you cannot directly read from the env object. You can only observe their real ranges as your agent explores the environment.
This is important because the models we will use today, and in part 5, work best with normalized inputs. In this case, normalized states. And to normalize a number you need to know first its max and min values. These 2 values for v and ω cannot be read from the env.observation_space . You need to estimate them using a bit of exploration.
The whole point of this note is:
⚠️ do not blindly take the values in `
env.observaton_spaceas the real ranges for each state.
What about the actions our agent can perform?
0: Push the cart to the left.1: Push the cart to the right.
The reward is +1 for every step taken. This means that the longer the agent keeps the pole standing, the higher the cumulative reward.
3. Random agent baseline 🤖🍷
👉🏽 notebooks/01_random_agent_baseline.ipynb
As usual, we use a RandomAgent to establish a baseline performance.

We evaluate this agent using 1,000 episodes

to compute the average reward and its standard deviation.

Let’s see how parametric Q-learning can help us build a smarter agent! 🧠
4. Parametric Q-learning 🧠
So far in the course, we have worked in discrete/tabular environments (in part 2) or transformed the original environment into a discrete one (part 3).
However, most interesting environments are not discrete, but continuous, and too large to be discretized and solved.
Fortunately, there are RL algorithms that directly work on continuous state spaces.
Today we are going to use Parametric Q-learning. This algorithm is analogous to the original Q-learning we saw in part 2 but adapted to work on a continuous setting.
The state-space for the CartPole consists of 4 continuous numbers
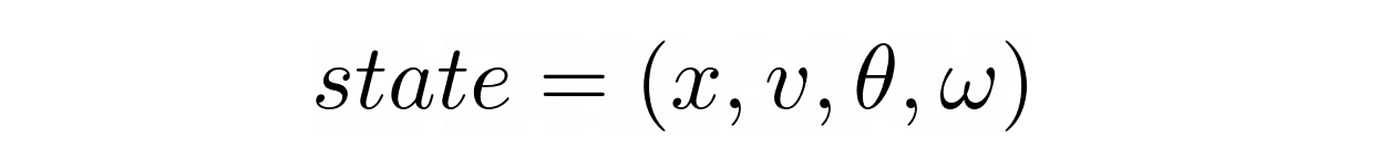
where
- x is the cart position
- v is the cart velocity
- θ is the pole angle
- ω is the pole angular velocity
In a continuous state space like this, the optimal Q-value function
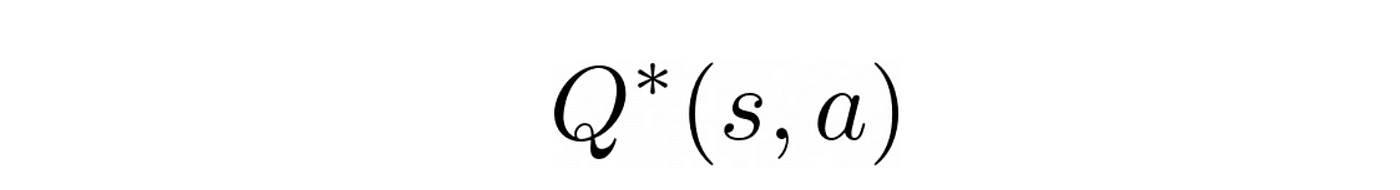
cannot be represented as a table (because it would have an infinite number of dimensions).
Instead, we represent it in using a parametric form

where
Q*is a model architecture, like a linear model, or a very deep feed-forward neural network.- that depends on a set of parameters we will estimate using the experiences (s, a, r, s’) the agent collects during training.
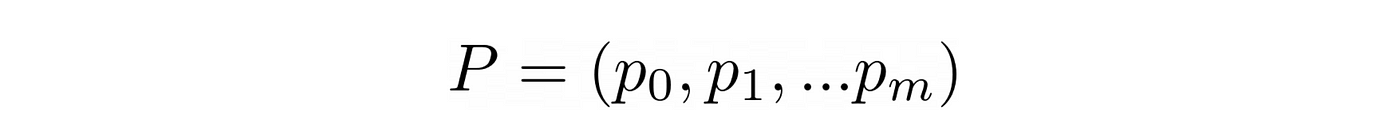
The choice of model architecture for Q* is critical to learning a good policy and solving the problem.
The more parameters the model has, the more flexible it is. And higher the chances are it is a good model for the problem. As a matter of fact, linear models are just a special case of neural networks, without intermediate layers.
Today we are going to use a linear model, to keep things simple, and in the next lecture, we will introduce a deeper (i.e more layers) neural network model to improve the performance.
Once you pick the model architecture for Q*, you need to find the optimal parameters P.
Ok, but how do you learn the vector of parameter P?
We need a method to iteratively find better estimates of these parameters P as the agent collects more experiences during training, and converge to the optimal parameters P*

Now, the function Q*(s, a, P) satisfies the Bellman optimality equation, a key equation in Reinforcement Learning
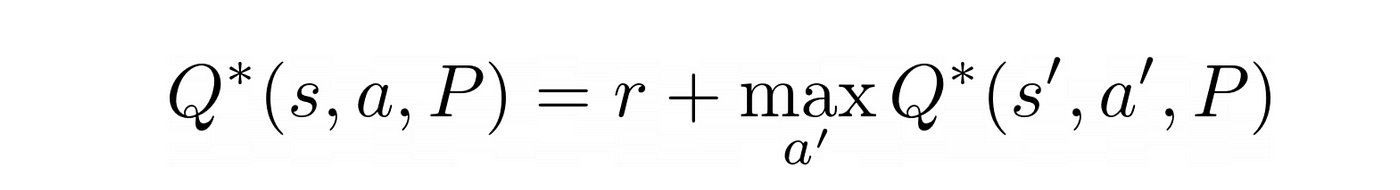
that tells us that the maximum future reward Q*(s, a, P) is the reward r the agent receives for entering the current state s plus the maximum future reward for the next state s’ .
The optimal parameters P* are those that bring the left-hand side of this equation as close as possible to the right-hand side.
This is an optimization problem that you can solve with modern Machine Learning techniques. More precisely, Supervised Machine Learning techniques.
A supervised ML problem has 3 ingredients:
- the input
featuresand correspondingtargets - a set of
parameterswe need to determine - a model architecture that depends on these
parametersand that mapsfeaturestomodel outputs
The goal is to find the parametersthat make the model outputs match the target values
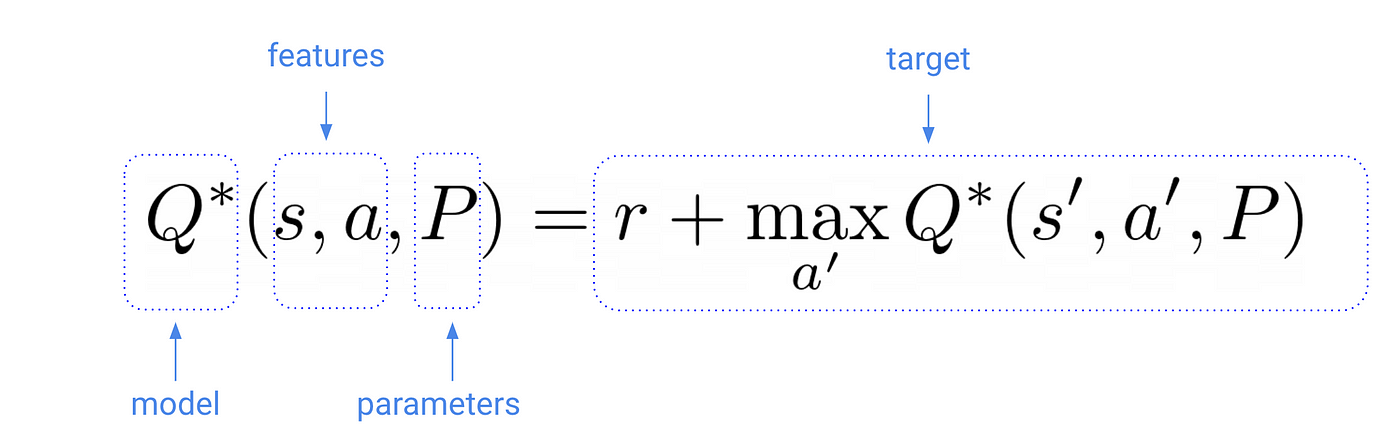
In other words, we want to find the parameters P* that minimize the distance, aka loss in the ML jargon.
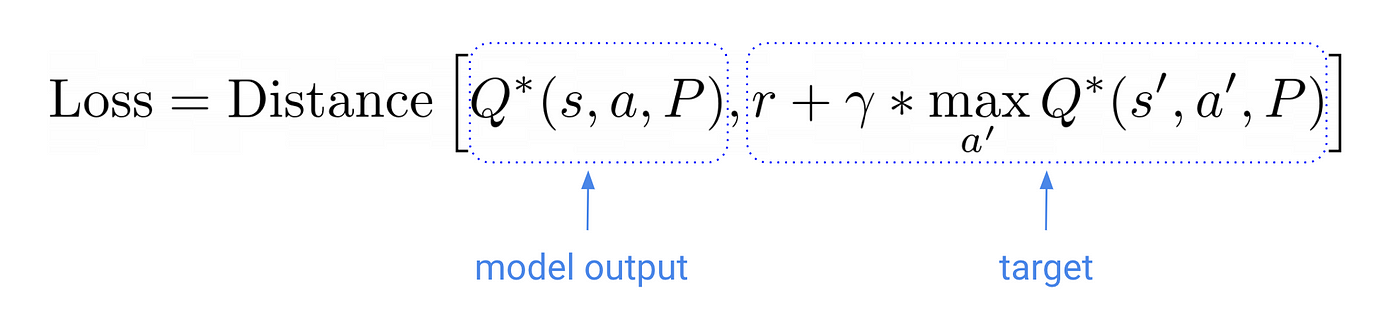
A classic algorithm to solve this optimization problem in the Machine Learning world is the stochastic gradient descent (SGD) method. More precisely, the mini-batch stochastic gradient descent.
Given your current estimate P⁰, a mini-batch of experiences (s, a, r, s’) and a suitable learning rate you can refine your estimation P⁰ with the SGD update formula
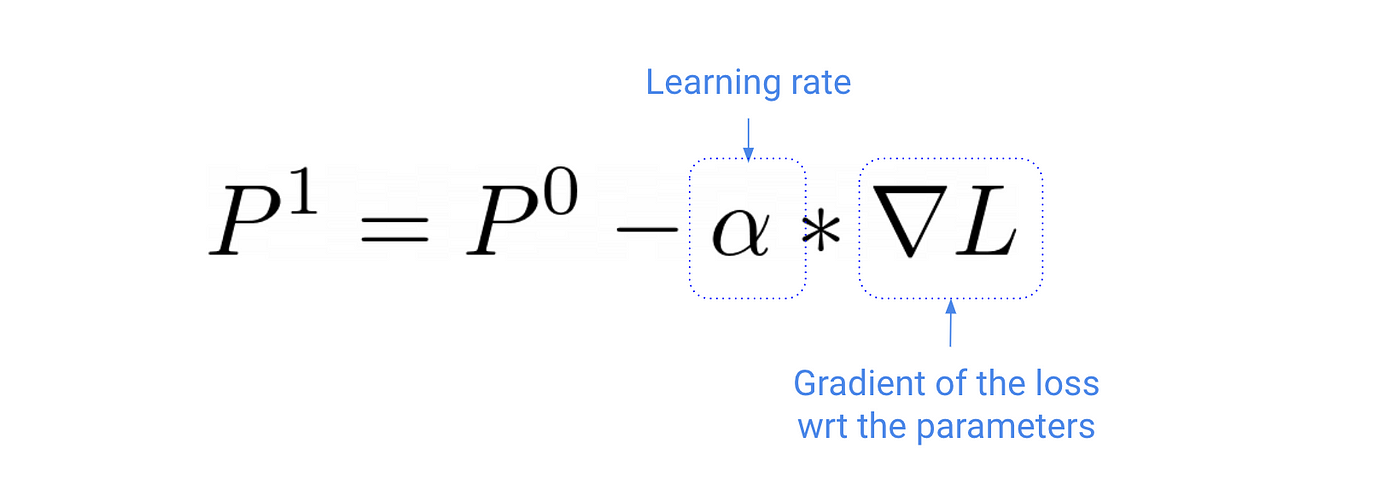
The gradient of the loss with respect to the parameters, ∇ L is a vector whose components are the sensitivities of the loss with respect to each of the components in the vector of parameters.
In practice, you will never need to compute gradients yourself. Python libraries like PyTorch or TensorFlow do it for you, using an algorithm called back-propagation, which is just a fancy name for the chain rule in calculus you might have learned years ago in high school.
Let’s recap:
- As our agent explores the environment, you collect batches of experiences, and you use these to update the parameters using the SGD update formula.
- If you repeat this long enough, you will (hopefully 🤞) get to the optimal parameters P*, and hence the optimal Q* value function.
- From the optimal Q* function you can derive the optimal policy

Voila! This is how Parametric Q-learning works!
But wait a sec…
Why did you say “hopefully converge to the optimal ones” above 👆?
As opposed to the tabular setting, where there are strong guarantees that Q-learning works, things are more fragile in the parametric version.
Essentially, what causes things to break is that the target values of our optimization problem
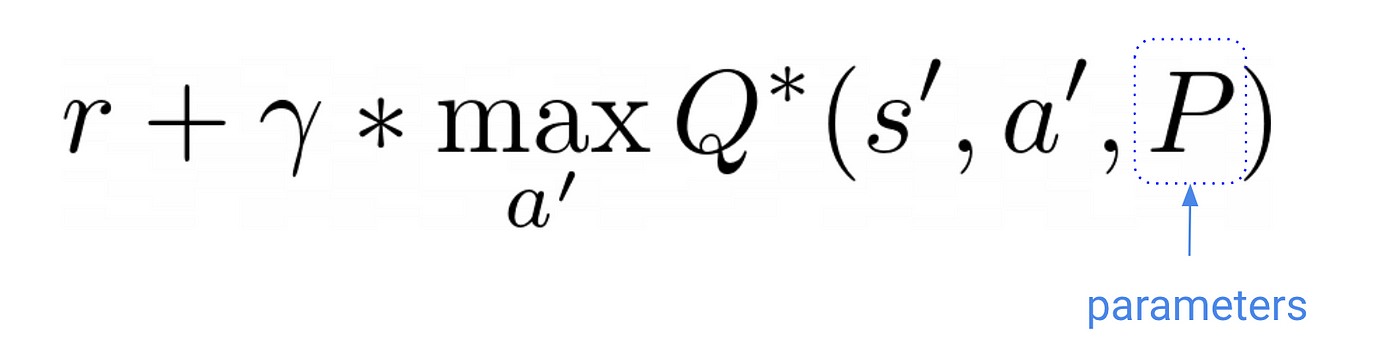
change as we update the parameter estimates. The targets change during training. They move 🏃
This apparently minor detail is what makes the problem harder to solve.
Hopefully, researchers got creative and introduced a few tips and tricks ✨ to solve the problem.
Trick 1: Slower update of the targets ✨
If moving targets is an issue, can we try to move them less?
The answer is yes. And we can do it by using 2 different vectors of parameters:
- P: parameters for the main model (left-hand side). These are adjusted after each SGD update. As expected.
- Pᵀ: parameters of the target model (right-hand side). These parameters are kept fixed during the SGD update, and we only reset them to match the ones in P every N-th iteration.
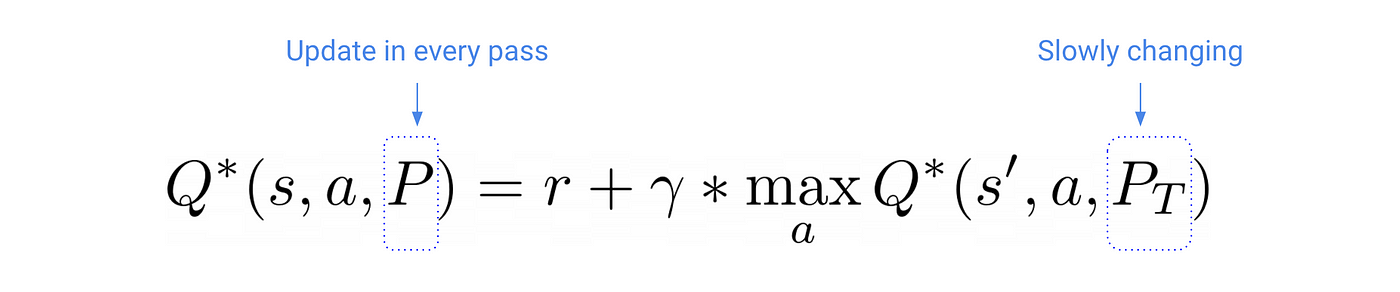
The frequency of update of Pᵀ is a hyper-parameter we will need to tune.
Trick 2: Replay memory ✨
Q-learning is an offline algorithm. This means the Bellman equation holds for any agent experience (s, a, r, s’), no matter which policy the agent followed.
Hence, past experiences can be grouped in batches and used to update parameters with the SGD update.
Creating batches of data like this removes the correlation between experiences, and this is especially useful to train neural network models faster.
How many experiences should we store in this memory?
This number (aka the memory size) is a hyper-parameter that we will need to tune.
Today you will need to trust me with the hyper-parameters we will use and wait for part 6 to see how we get to them.
Tunning hyper-parameters is not an art, but a science.
We will see in part 6 how to do it using the very popular Python library Optuna
Finally, if you have already built neural network models with the PyTorch library you can skip the next section. Otherwise, let me introduce you to your next best friend 🤓
5. Hello PyTorch! 👋
PyTorch is a Python library that lets you train differentiable models, including linear models and neural networks.
It is going to be THE library we will use for the rest of the course for the kind of Supervised ML problems we need to solve in Parametric Reinforcement Learning algorithms, like Parametric Q-learning.
PyTorch has a very Python interface (as opposed to Tensorflow) and I am sure you will pick it up fast.
The key feature behind PyTorch is its automatic differentiation engine, which computes for us the gradients we need to update the model parameters.
The main building blocks of a training script in PyTorch are:
👉 A batch of input data, containing the features and the target.
👉 The model definition encapsulated as a Python object torch.nn.Module You only need to implement the forward pass, i.e. the mapping from inputs to outputs. For example,

👉 A loss function, for example, torch.nn.functional.mse (mean squared error) that computes the loss given the model output and the target.
👉 An optimizer, like torch.optim.Adam (a sophisticated version of SGD) that adjusts the model parameters to decrease the loss function on the batch input data.
These 4 ingredients are combined in a loop, aka the training loop of a Supervised Machine Learning problem.

At the end of this script, if your model architecture is appropriate for the data, your model parameters will be such that the model_outputis very very close to the target values

This is how you solve a parametric function approximation with PyTorch.
Enough talking. Let’s move to the code and implement a Linear Q agent!
6. Linear Q agent
We use the following model to map input states to q-value functions (aka our q function):
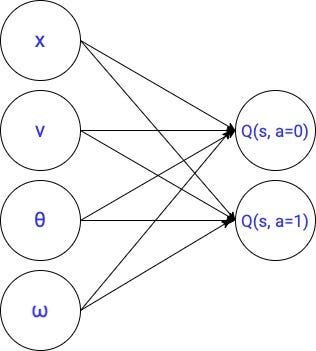
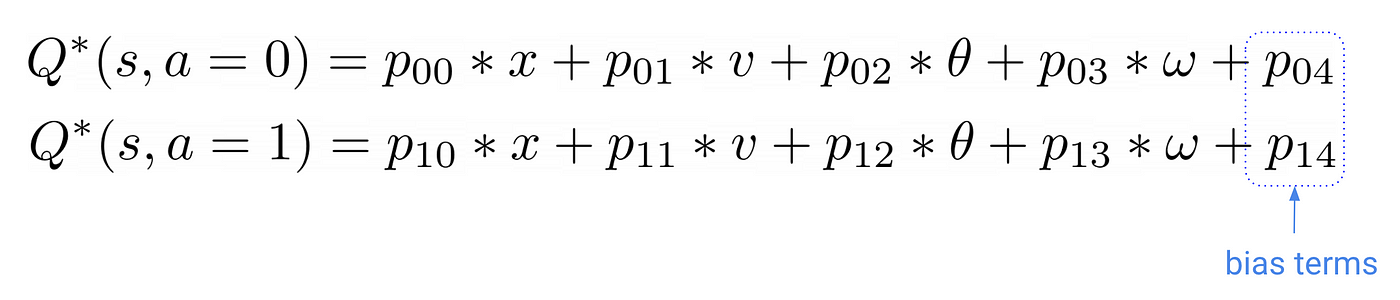
The number of parameters is equal to the number of connections between the inputs and the output cells (i.e. 4 x 2 = 8) plus 2 bias terms we usually add to these linear layers to augment their expressiveness. This gives a total of 10 parameters.
This is not a very flexible model, but it is enough for today. In the following lecture, we are going to use more powerful neural network models.🤑
Now, let’s go to the hyperparameters…
I created 2 notebooks. One with bad hyper-parameters and the other with good ones.
In two lectures we will see how to experimentally find these values. For the moment, trust me they are the best (and worst) I could find 🙂
Bad hyper-parameters
👉🏽 notebooks/02_linear_q_agent_bad_hyperparameters.ipynb
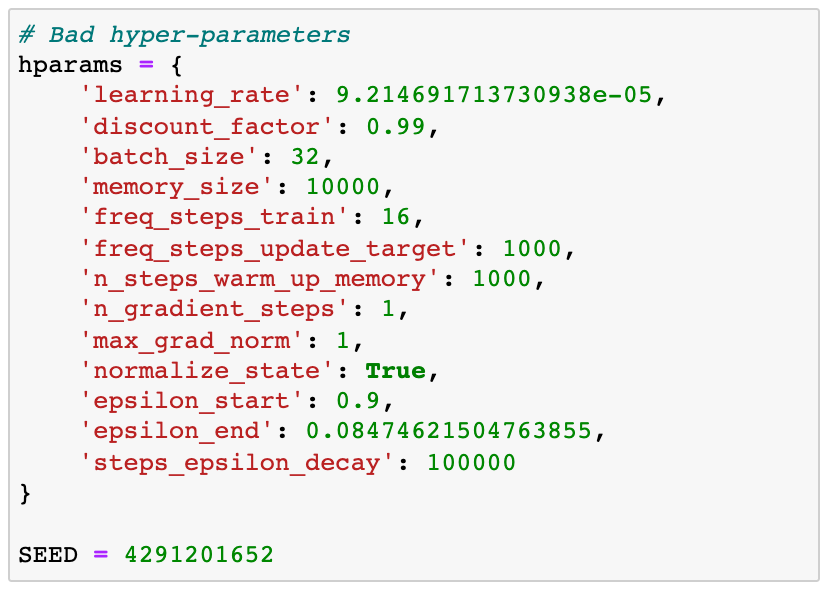
We fix all random seeds to ensure reproducibility

Then we create the QAgent object

and we train it for 2,000 episodes:

We evaluate its performance on 1,000 random runs

And the results look…

pretty bad!
They are similar to the baseline RandomAgent😵!
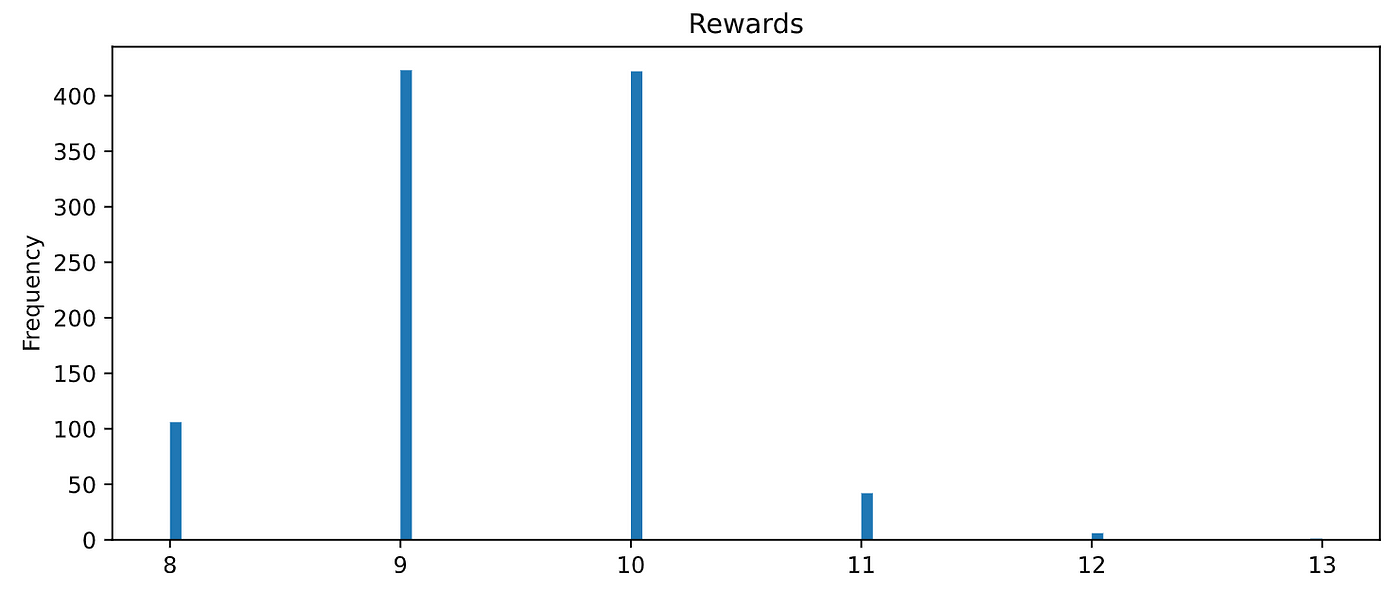
Let’s see what happens when you use good hyper-parameters.
Good hyper-parameters
👉🏽 notebooks/03_linear_q_agent_good_hyperparameters.ipynb
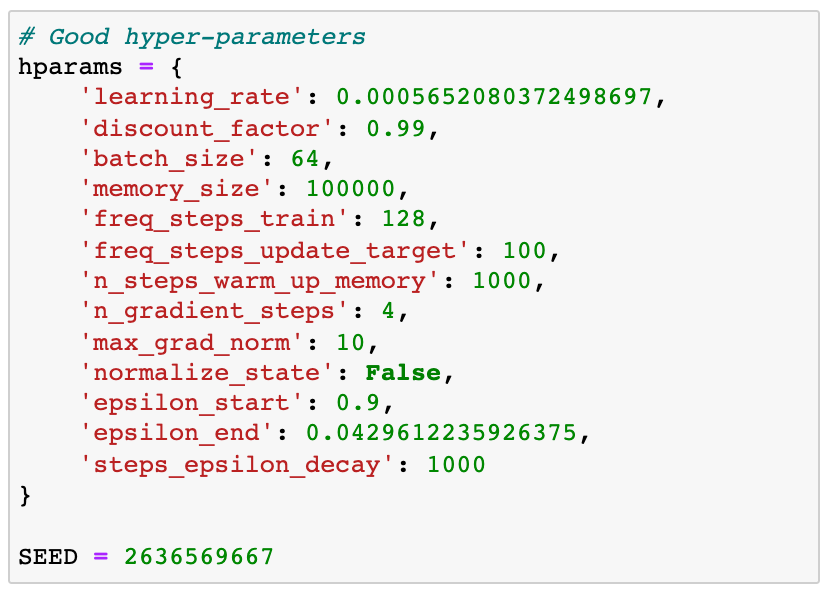
We repeat the same steps to train the agent, and then we evaluate its performance:

Amazing results!
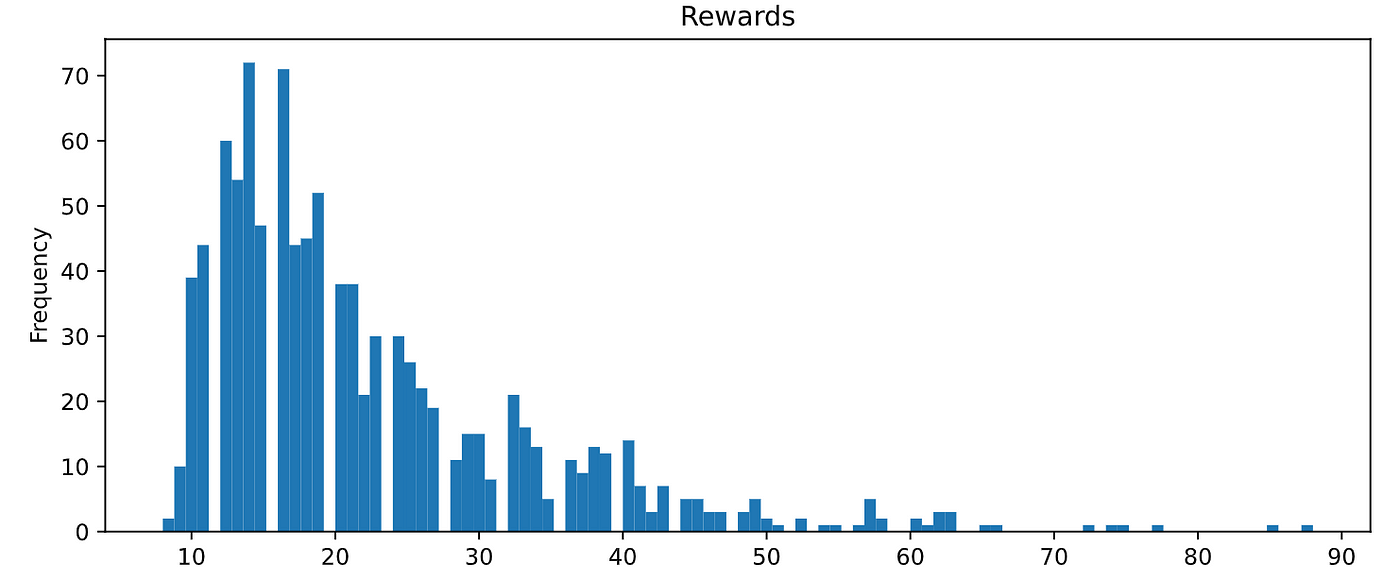
You can plot the whole distribution to see that the agent consistently scores above 100! 🎉🎉🎉
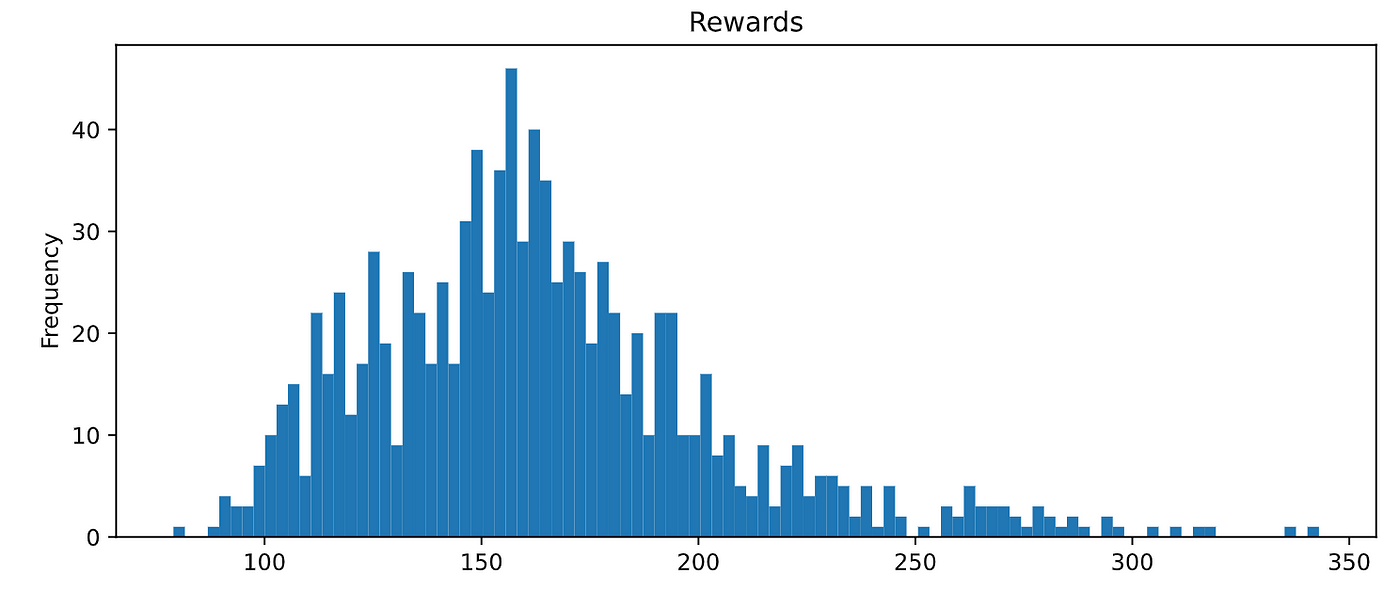
Wow! What a colossal impact the hyperparameters have on the training outcome.
Hyper-parameter sensitivity
Reinforcement Learning agents that use parametric approximations are very sensitive to hyper-parameters. Often, they are also sensitive to the random seed you use to control all sources of randomness during the training.
This makes it very hard to reproduce results published in papers and journals unless ALL hyper-parameters are provided.
There is a great paper about reproducibility in Modern/Deep Reinforcement Learning that I highly recommend you to read
We made enough progress today, building our first parametric Q agent.
Time to stop and recap.

7. Recap ✨
These are the 3 key takeaways:
- Parametric Q learning is a powerful algorithm that combines classic RL (Q-learning) with function approximation (Supervised ML).
- The parametrization you use is key to ensuring the algorithm converges to an optimal solution. Today we used a linear model, but in the next part, we will use a more flexible model: a neural network.
- Hyper-parameters are critical and can be a deal-breaker.
8. Homework 📚
👉🏽 notebooks/04_homework.ipynb
This is what I want you to do:
- Git clone the repo to your local machine.
- Setup the environment for this lesson
03_cart_pole - Open
03_cart_pole/notebooks/04_homework.ipynband try completing the 2 challenges.
In the first challenge, I want you to try different SEED values and re-train the agent using the good hyper-parameters I showed you. Do you still get good performance? Or do the results depend a lot on the SEED you used?
In the second challenge, I ask you to use today’s method and code to solve the MountainCar-v0 environment from part 3. Are you able to score 99% score using linear Q-learning?
9. What’s next? ❤️
In the next lesson, we are going to throw in our first deep neural network and create our first Deep Q Agent.
Exciting, isn’t it?
Let’s keep on learning together!
If you want to get updates on the course subscribe to the datamachines newsletter.