
Ready to implement a kick-ass deep q learning agent from scratch?
Let’s get deeper! 🙏 Jeremy Bishop from Pexels for this beautiful image.
Welcome to my reinforcement learning course ❤️
This is part 5 of the Hands-on Course on Reinforcement Learning, which takes you from zero to HERO 🦸♂️.
- Introduction to Reinforcement Learning
- Tabular Q-learning
- Tabular SARSA
- Linear Q learning
- 👉🏻 Deep Q learning (today)
In part 4 we built an okay-ish agent for the Cart Pole environment. We used parametric Q learning with a linear model.
Today we will replace this linear model with a neural network.
And we will kick-ass-solve the Cart Pole environment 😎 using deep Q learning.
Today’s lesson is a bit longer, as it includes a mini crash course on training neural network models. Unless you are an expert in deep learning, I highly recommend you do not skip it.
All the code for this lesson is in this Github repo. Git clone it to follow along with today’s problem.
And if you like the course, please give it a ⭐ in Github!

Take a long sip ☕. We are ready to start!
Part 5
1. Let’s go deep! Enter Deep Q learning
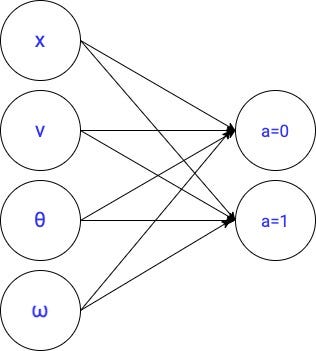
In the previous lesson, we used this linear parameterization to represent the optimal q function.
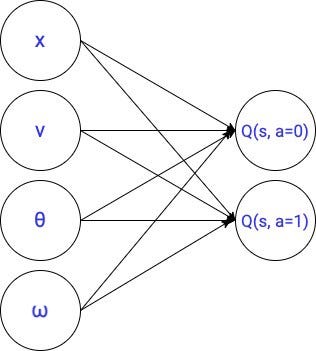
This is a small model with only 10 parameters.
The success (or failure) of a parametric Q-learning agent strongly depends on the parameterization we use to approximate the optimal q value function.
Linear models are conceptually simple, fast to train, and fast to run. However, they are not very flexible. Given a set of inputs and outputs, linear layers struggle to map inputs to outputs.
And this is when neural networks enter into the game.
Neural network models are the most powerful function approximations we have. They are extremely flexible and can be used to uncover complex patterns between the input features and the target labels.
The Universal Approximation Theorem 📘 is a mathematical result that essentially says:
Neural networks are as flexible as you want them to be. If you design a sufficiently large neural network (i.e. with enough parameters), you will find an accurate mapping between the input features and the target values.
Or if you prefer a more philosophical touch…

Today we are going to replace the linear model from part 4 with the most simple neural network architecture out there: a feed-forward neural network.
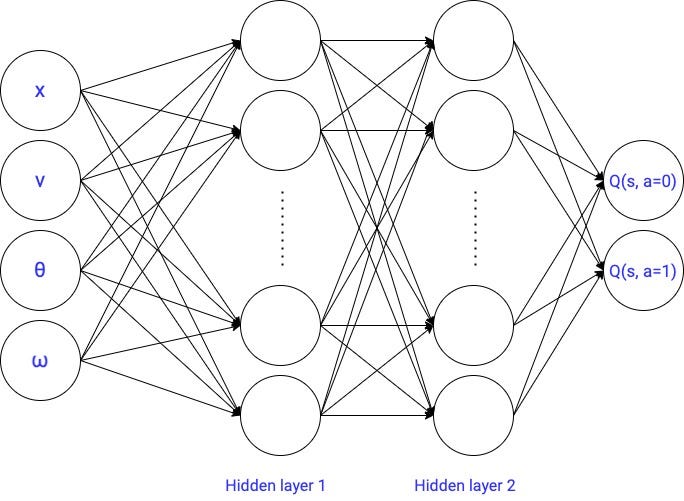
This is the first deep q learning agent we build in the course. Exciting, isn’t it?
Later in the course, we will use other neural networks to deal with more complex states spaces (e.g. convolutional neural networks).
As I said at the beginning of the course, I do not expect you to be an expert in neural networks.
If you are indeed one, feel free to skip the next section and go straight to section 3.
Otherwise, let us warm up our deep learning mastery with the following imitation learning problem I created for today.
There is quite a lot to cover, so arm yourself with deep focus.
2. Hands-on Introduction to Deep Learning: learning the optimal policy from labeled data
👉🏽 notebooks/05_crash_course_on_neural_nets.ipynb
In this section, we will solve a Supervised Machine Learning problem using Deep Learning.
But, why don’t we just solve the Cart Pole? 🤔
The key difference between a Supervised ML problem and the optimization we solve in parametric Q-learning, is that in Supverside ML the targets are fixed while in parametric Q-learning they are NOT fixed, but move.
Because of this, Supervised ML problems are easier to solve, and hence they are a better starting point to get our hands dirty with Neural Network models.
In Supervised Machine Learning, you have a dataset of pairs (input, outputs) and you want to find the right mapping between inputs (aka features) and outputs (aka targets/labels).
Ok, what is the Supervised ML problem we are going to solve?
I took the perfect deep-q agent we will train in the next section (aka the perfect agent) and generated a sample of 1,000 states (the inputs) with the corresponding actions taken by this perfect agent (the outputs). From this sample of observations, we want to learn the underlying optimal policy the agent follows.
Think of it as an imitation learning problem. You are given 1,000 samples (state, action) from an expert performance, and your job is to learn the underlying strategy the agent follows.
Enough talking. Let’s look at the code. We first see how to generate the training data. Then we will train several neural network models and extract some learnings.
2.1 Generate the train data
As usual, we start by loading the environment

To generate the training data we first need to get the perfect agent parameters (and hyperparameters). I uploaded these to a public Google Drive you have access to, and from where you can download them as follows:

In path_to_agent_data you have 2 files:
model→ saved PyTorch model with the parameters of the parametric function, in this case, a neural network.hparams.json→ hyper-parameters used to train the agent
Now, you can instantiate a QAgent object from these parameters (and hyper-parameters) as follows:

Before going further, I want you to believe me when I say the agent is perfect. Let’s evaluate it in 1,000 random episodes and check the total reward.

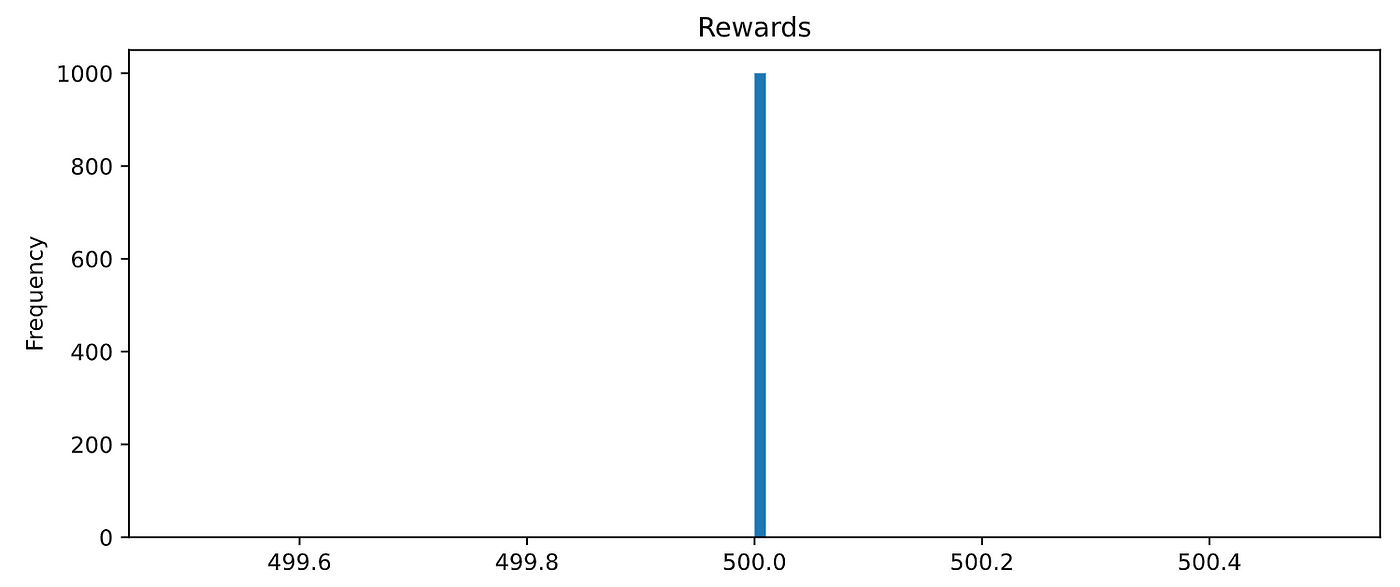
500 is the maximum total reward, and our agents got it in all 1,000 episodes. Fantastic! You will need to wait until the next section to train this perfect agent yourself.
Now, we let the agent interact with the environment for a few episodes until we have collected 1,000 pairs (state, action). This is how we generate our train data.

The generate_state_action_data function generates a CSV file that looks like this:
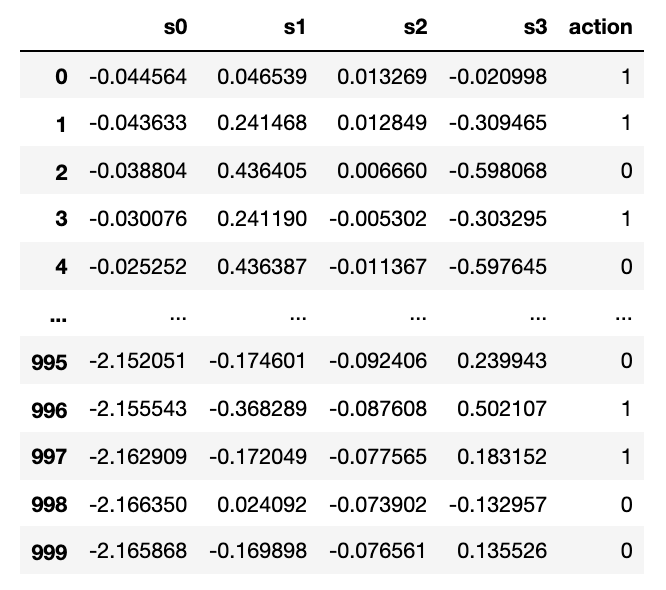
Where:
s1, s2, s3, s4are the input features, andactionis the target, in this case, a binary target (0 or 1). We will be solving a binary classification problem.
Now, before we jump into the modeling part, we still need to do one thing.
When you train Supervised ML models (especially neural networks) and you want to correctly assess their accuracy, you CANNOT use the same dataset you used to train them.
Why?
Because it might happen that your model simply memorized the train data, instead of uncovering the true correlations between the features and the targets. This can easily happen with highly-parametric models, like large neural networks. Hence, when you use the model for new and unseen data by the model, your model performance will be lower than what you got during training.
To solve this, we generate another dataset, called test data, that we do not use to adjust any model parameter. The test data is used exclusively to evaluate the performance of the model.
We generate in the same way as the train set.
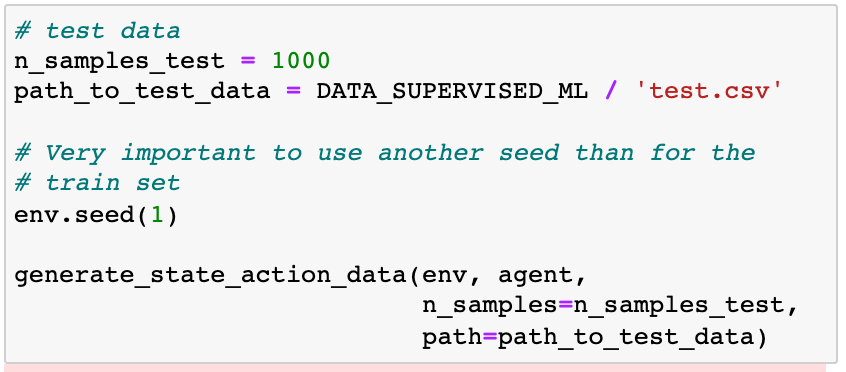
Observe how we used a different seed than for train.csv , to guarantee that we are not generating the same samples for the train and test datasets.
Cool. We got the data. Let’s move on to the modeling part.
2.2. Modelling
As we always do in our Reinforcement Learning problems, it is best to start by building a quick baseline model, to get a sense of how hard the problem is.
Let’s load the CSV files:

If we inspect the train data we can see that the target value (i.e. the optimal action) has a completely balanced distribution.
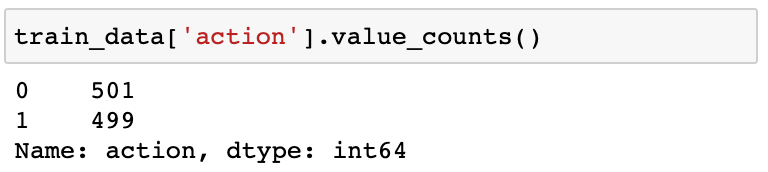
This means that a very dummy baseline model that predicts always action = 0 (or action = 1) has an accuracy of 50%, which means the model prediction matches the correct label 50% of the time.
Loading data into your PyTorch model
Before we jump into the models, we need to build a data pipeline to quickly move data in batches from the pandas data frames to our PyTorch model.
PyTorch API offers 2 auxiliary objects to let you do this easily:
torch.utils.data.Dataset→ convenient wrapper around your panda’s data frame. It retrieves the dataframe features and labels one sample at a time.torch.utils.data.DataLoader→ does the heavy lifting for you, moving the data from theDatasetto the Pytorch model in batches. It uses Python’smultiprocessinglibrary to speed up data retrieval.
We need two data pipelines, one for the train data and one for the test data.

We create a custom Dataset class, and implement 3 must-have methods: __init__() , __len__() __getitem__(idx).

Then, we instantiate 2 Dataset objects:

The DataLoaders are even easier to implement, as we only need to declare them, as follows:

Good! The data pipelines are ready. Now we have a way to quickly move data in batches and feed them to the models we will build.
All models will be trained using the Cross-Entropy loss function, which is a standard choice for classification problems.

We will use TensorBoard to visualize train and test metrics (loss and accuracy). Even though it was developed by Google for its DL framework TensorFlow, Tensorboard has a very neat integration with PyTorch.
2.2.1 Linear model → 10 parameters
This is our first candidate to learn the optimal policy.
We create the PyTorch model as follows:

We train this model for 150 epochs. An epoch is a full pass over the entire train data. Hence, we are going to use each sample in the training data 150 times to adjust the model parameters
At the end of each epoch, we compute the model loss and accuracy using the test data. This way we get a measure of how good the model is.

Let’s fire up the Tensorboard server to visualize the train and test metrics. We can do it from the Jupyter notebook

Note: you can start Tensorboard directly from the command line if you prefer, and navigate to the URL printed on the console, in my case
localhost:6009/

Open Tensoboard and select the latest run. You should see these 2 charts:
- Accuracy on the train data, batch after batch. It plateaus around 70%.
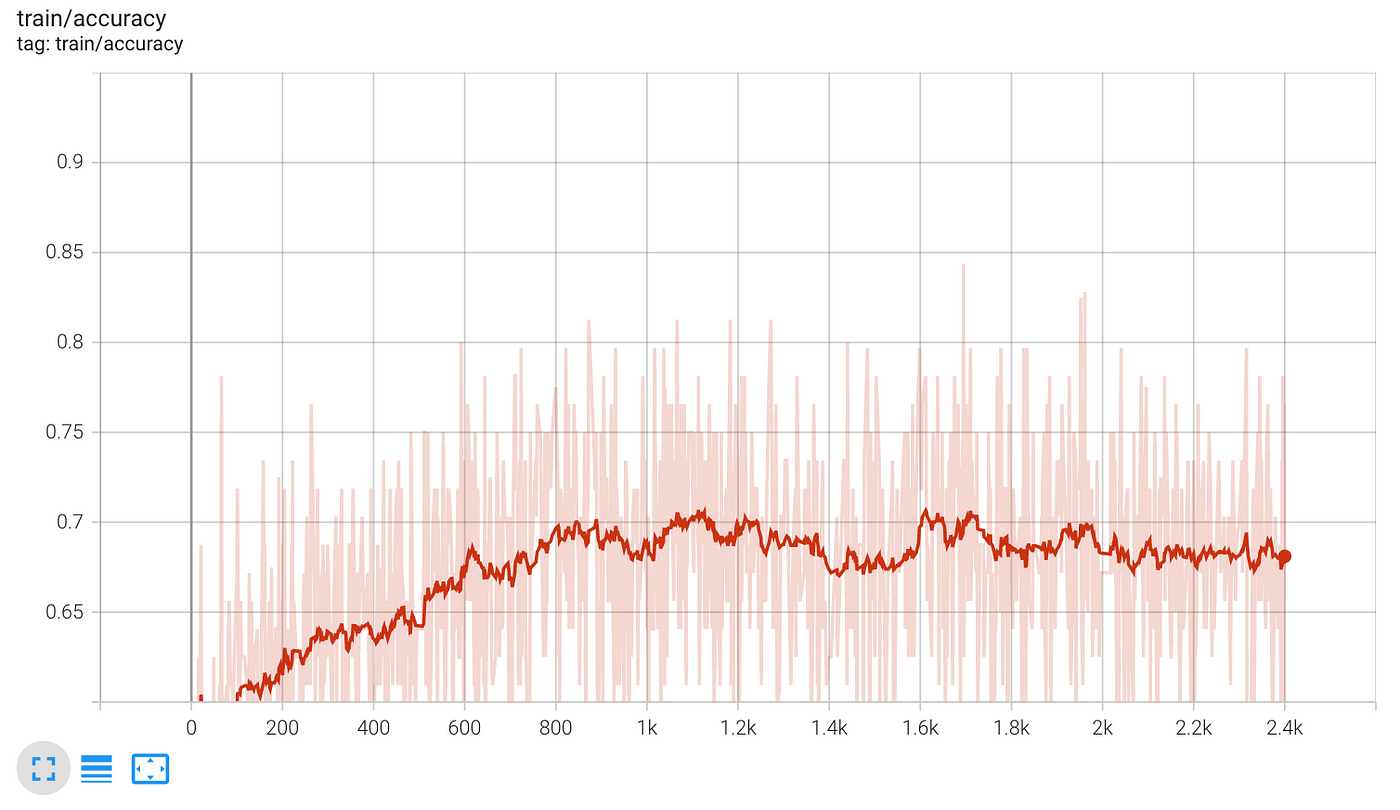
- Accuracy on the test data, batch after batch. It also plateaus around 70%. This number is larger than the baseline of 50%, so the model is learning something.

70% is not that bad, but it is also far from perfect.
💡Tip: Plot train metrics to detect bugs
Always plot the train accuracy and loss, as it can help you find bugs in your code. If the accuracy (loss) does not increase (decrease) after each epoch, it means your network is not learning. This is probably due to a bug in your code that you need to fix.🧠 Learning: Underfitting the train data
If the model is to small for the task, we observe both train and test accuracy plateau at a modest level, in this case 70%. We say the model underfits the data, and we need to try a larger model.
Let’s expand the network to improve results.
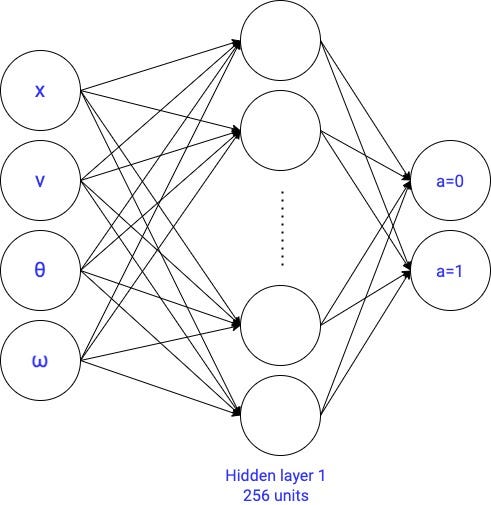
2.2.2 Neural network with 1 hidden layer → 1,795 parameters
We create a neural network with one hidden layer with 256 units:

We train it for 150 epochs and then go to Tensorboard to check metrics
- Accuracy on the test data. We improved from 70% to around 85%.
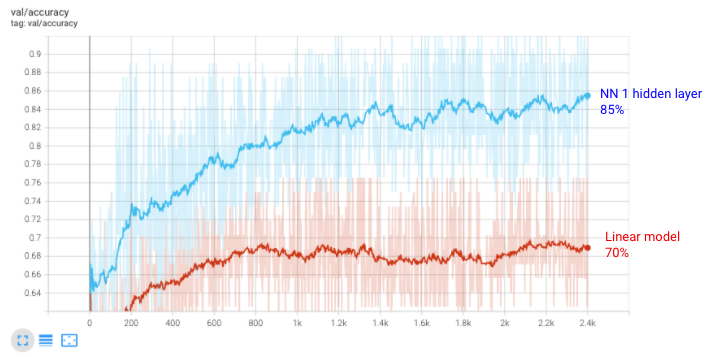
85% looks much better. But still, I think we can do better than that. Let’s try a larger neural network.
2.2.3 Neural network with 2 hidden layers → 67,586 parameters

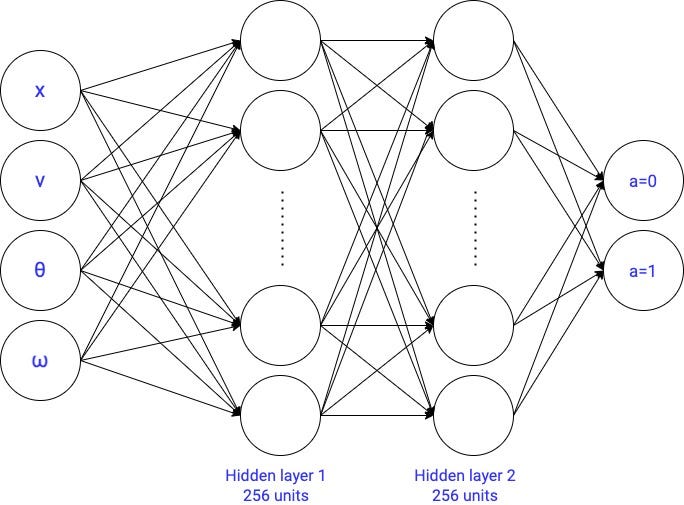
You will observe its test accuracy hits 90%.
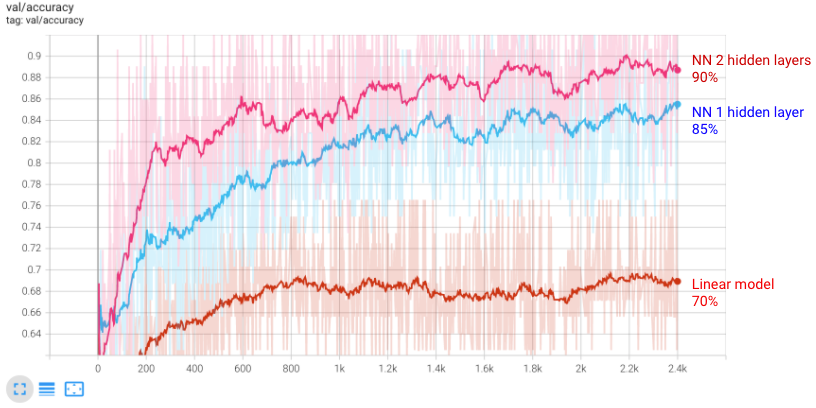
Increasing the network size seems to be a smart strategy. Let’s go one step further and add one more layer.
2.2.4 Neural network with 3 hidden layers → 133,378 parameters

If you go check its accuracy on test data, you will see it gets to 90%. Hence, this model does not improve our best results.
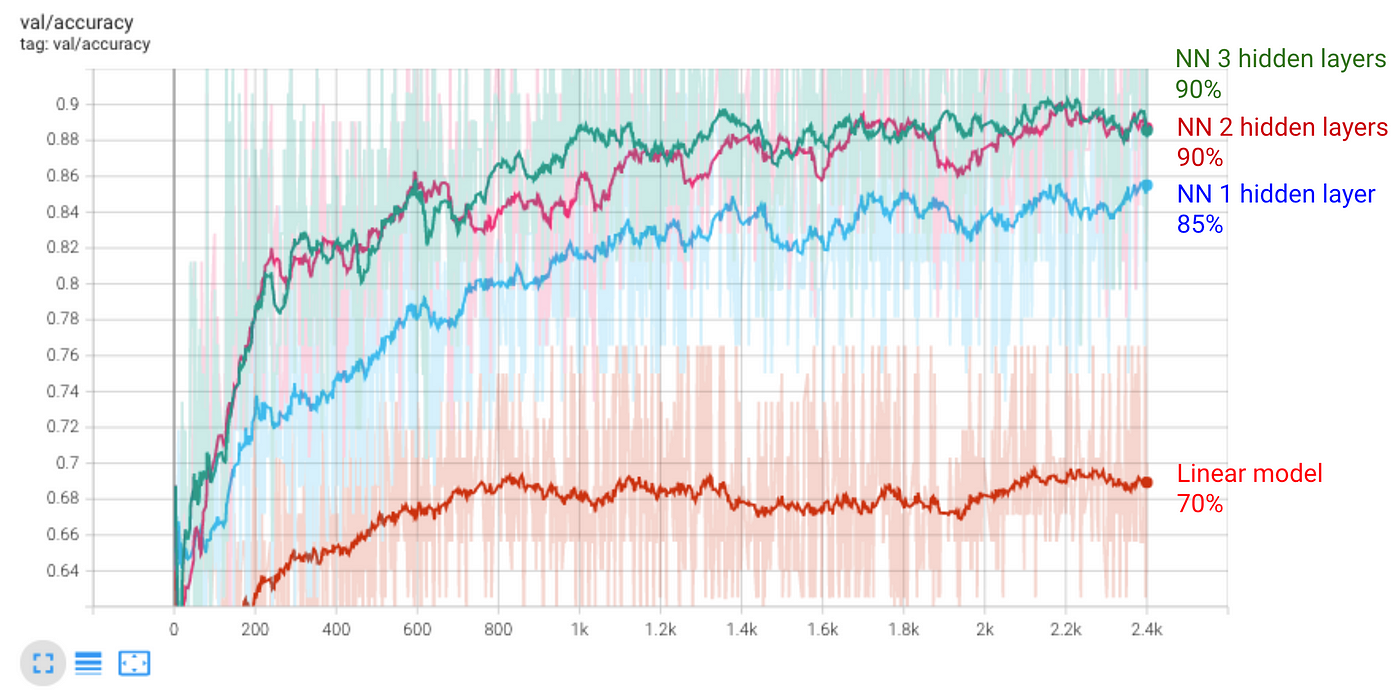
Intuitively, it seems that our previous model, with 2 hidden layers and around 67k parameters, did the job well enough. Using a more complex model does not really bring better results.
🧠 Learning: Overfitting the train data
If your model is too large compared to the amount of training data, you will overfit the train data. To detect overfitting take a look at the train and test losses.
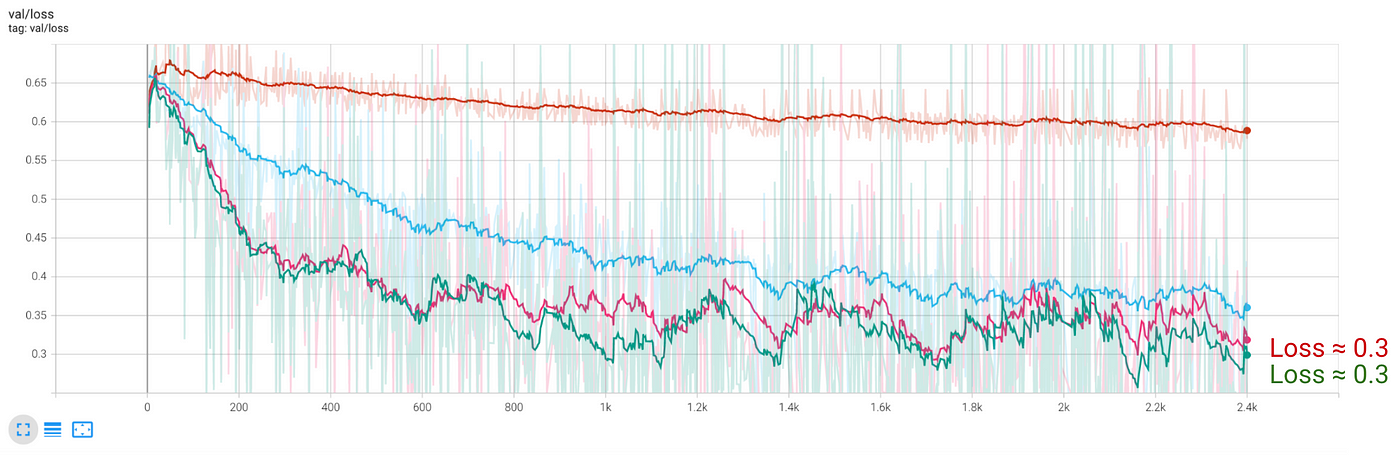
If the train loss continues to decrease, while the the test loss plateaus, it means you started to overfit
We can check overfitting in this case by looking at the train and test losses:
- Loss on train data almost gets to 0.
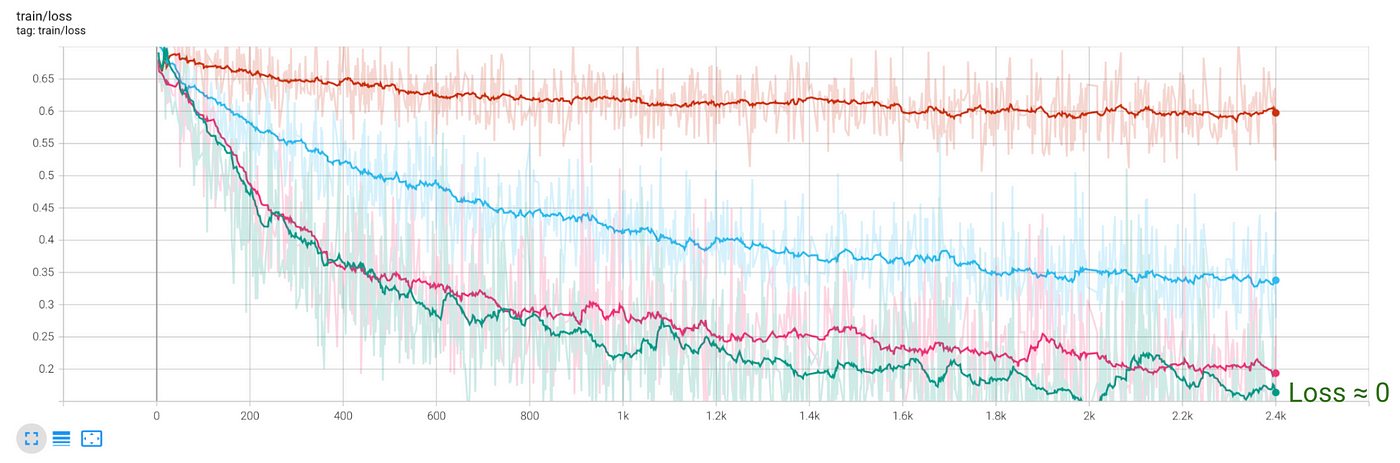
- Loss on test data plateaus at 0.3, which is the same as for the previous model with 2 hidden layers.
💡Tip: Collect more data to improve results
The most effective strategy to improve a neural network model is to use a larger train set. This advice applies to any Machine Learning model, not only neural networks. However, neural networks are the ones that benefit the most from larger train sets, as they are highly parameteric and flexible to adapt to the most complex patterns in the data.
As you see, there is quite a bit of experimentation to find the right neural network architecture for the problem.
You might be asking…
Is there a systematic way to find the right architecture for my data?
Yes, there is. In this section, we went from small models to large models, in order to add complexity progressively. However, in practice, you should go the other way.
💡Tip: Go from large to small
In general, you should start with a large enough network that overfits the training data. Once you are sure the network has enough capacity, you start reducing it, to decrease overfitting on the train data and increase accuracy on the validation data.
Andrej Karpathy has a very good blog post on this, that I highly recommend you to read
📝 A Recipe for Training Neural Networks
I hope that after this section you have a better understanding of how to train neural network models.
I recommend you go through the code in src/supervised_ml.py to consolidate what we covered in this section. Training neural network models in a supervised setting is a very practical use case of deep learning in the real world. Practice 100x times, and let me know if you have questions 📩.
In the next section, we go back to the Cart Pole problem.
Are you ready to mix RL with what you just learned about neural networks?
3. Deep Q learning to solve the Cart Pole
Back to parametric Q-learning and the Cart Pole.
We will entirely reuse the code from part 4, with the only difference that we will replace the linear parameterization of the optimal q function
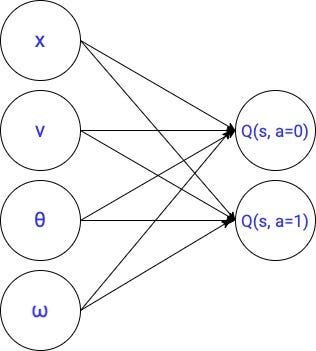
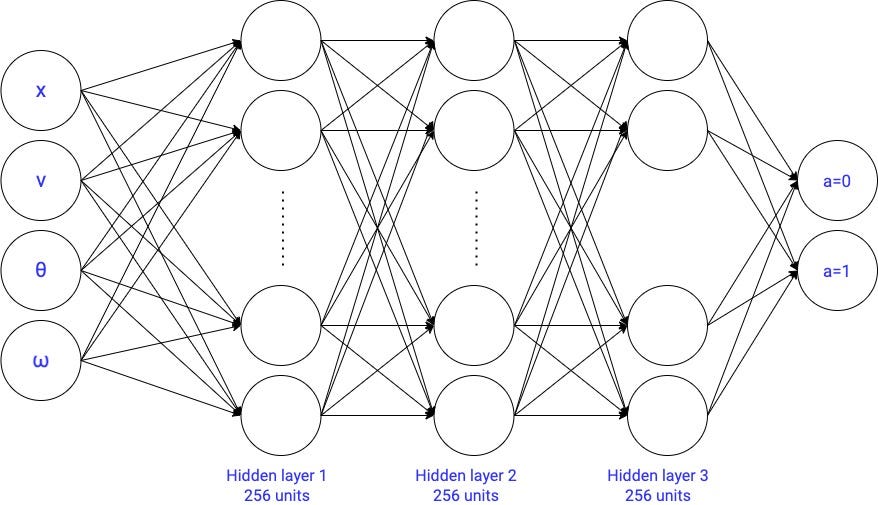
with a neural network with 2 hidden layers
This is going to be the first Deep Reinforcement Learning algorithm in the course. In this case, a Deep Q-network.
What about the hyperparameters?
RL algorithms are extremely sensitive to hyper-parameters. And Deep Q-learning is not an exception.
I am not going to lie to you. Finding the right hyper-parameters can be very time-consuming. Hyper-parameters are critical in Deep Reinforcement Learning, and many authors do not publish them. And this is quite frustrating for anyone entering the field.
Even the randomness in the training loop, coming for example, from the shuffling of batches of train data in the memory, can have a big impact on the final agent parameters.
Because of this, we always fix all the seeds at the beginning of our Python script

However, this is not enough to ensure reproducibility across machines. It can happen that both you and I use the same hyper-parameters and random seed, but we get different models just because you are training on a GPU while I am not.
In other words, completely reproducible results are not guaranteed across PyTorch releases, different platforms, or hardware setups (GPU vs CPU).
Reproducibility of results
You might not get the same results as I did when using the exact same hyperparameters I share in this section.Do not get frustrated. In the next lesson, we will learn how to tune the hyperparameters ourselves, and you will be able to find those that kick-ass for your setup in case these do not work for you.
Bad hyper-parameters
👉🏽 notebooks/06_deep_q_agent_bad_hyperparameters.ipynb
These hyperparameters were not the worst I found, definitely. I call them bad because they give similar results to our linear q-model from part 4.
What is the point of using a complex neural network model when the hyper-parameters are badly set?
These are the hyper-parameters:
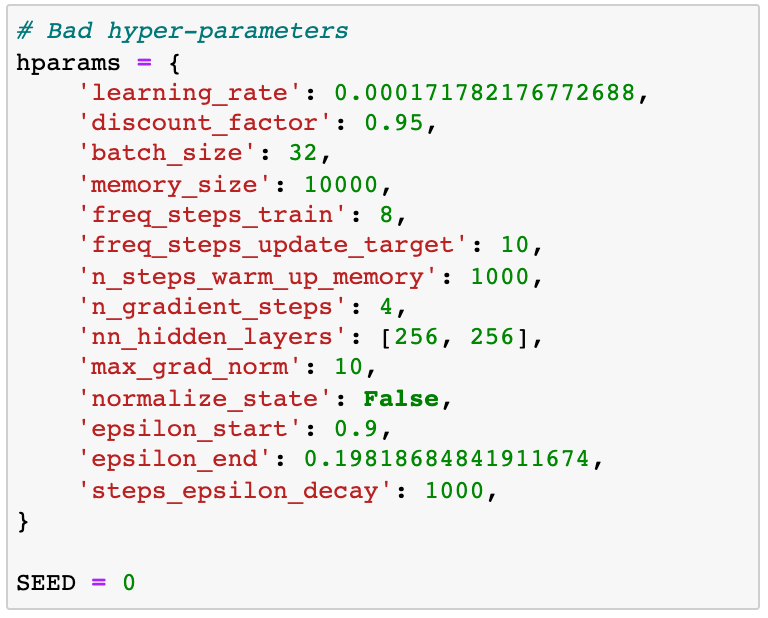
As usual, we fix the seed

We declare the QAgent from these hyper-parameters

And we train for 200 episodes:

Then we evaluate the agent on 1,000 new episodes
The results are okish, but we can do better than this.
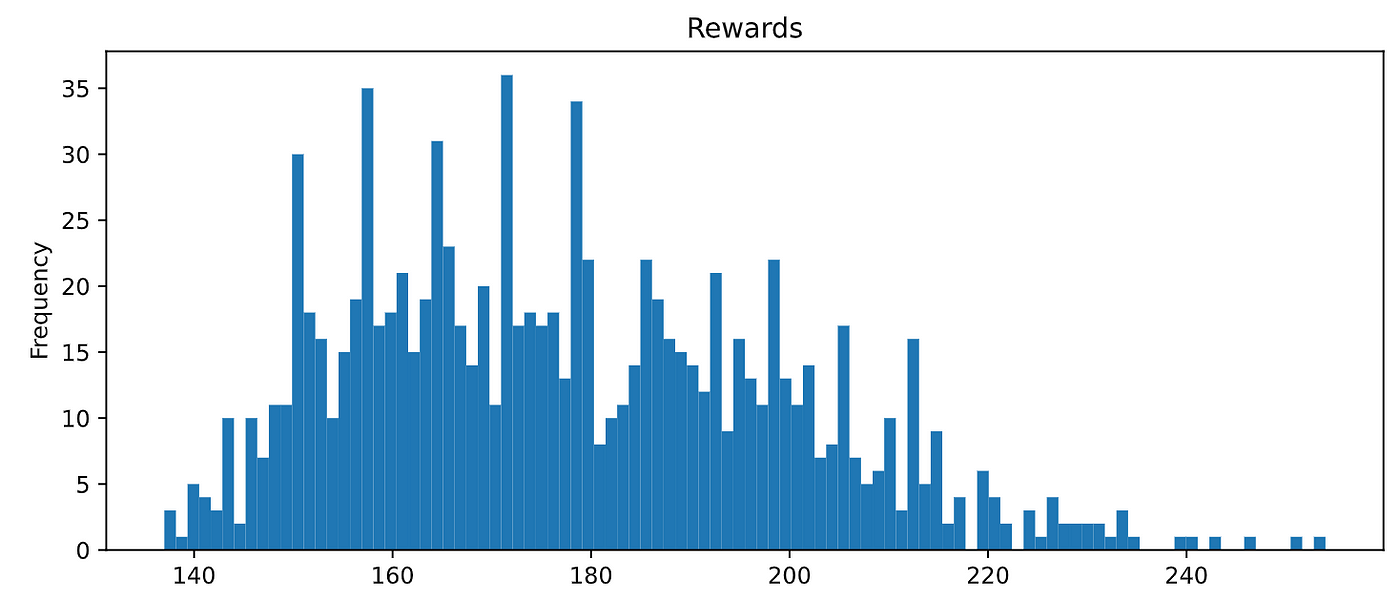
Let’s do it then!
Good hyper-parameters
👉🏽 notebooks/07_deep_q_agent_good_hyperparameters.ipynb
These hyper-parameters worked like a charm on my MacBook:

As usual, we fix the seed
We declare the QAgent from these hyper-parameters
And we train for 200 episodes:
If you evaluate the agent on 1,000 episodes
You will see it hits 100% performance:
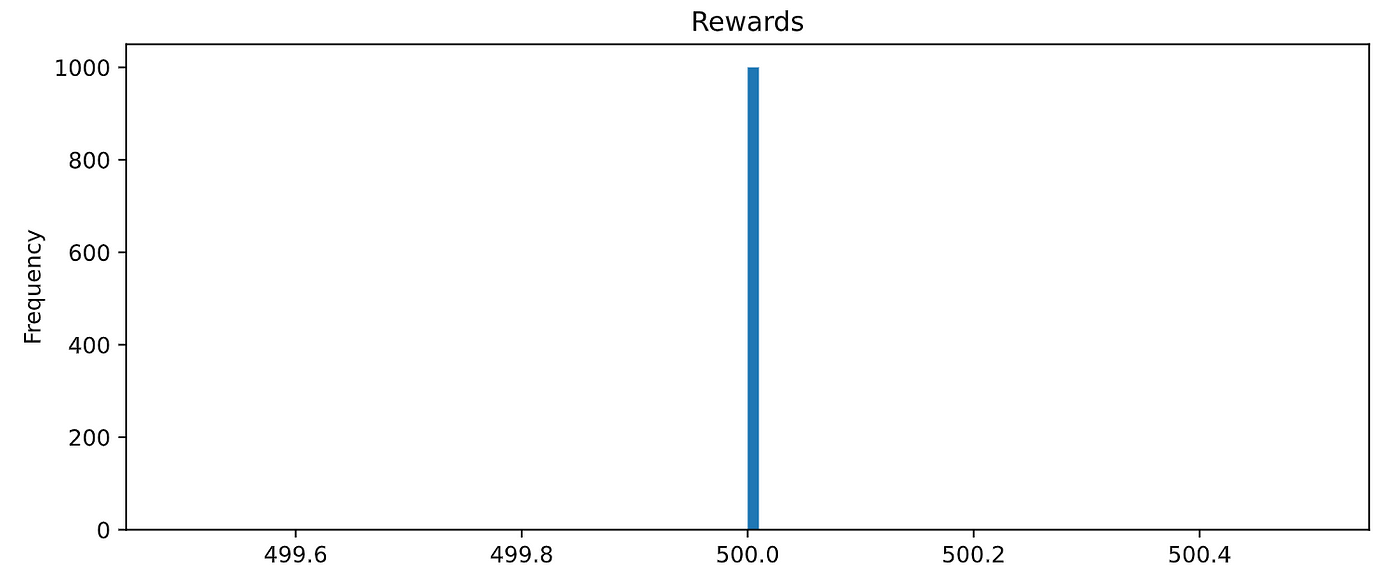
Wooowww!! Amaaaziiiing!!!
That is pretty cool. We found the perfect deep q-agent in the CartPole environment! (And if you haven’t yet in your computer, wait for part 6 and I will reveal the science and engineering behind hyper-parameter tunning 😉).
That was all for today folks.
Hungry to learn more?

4. Recap ✨
These are the key learnings I want you to extract from today’s lesson:
- Neural networks are very powerful functional approximators. You can use them in a fully supervised setting (e.g. learn optimal policy from labeled data) or as a component of an RL algorithm (e.g. to approximate the optimal q-value function).
- Finding the right neural network architecture is not easy. Too large (small) of a neural causes overfitting (underfitting). In general, start with a large network that overfits the training data. Then you start reducing it to improve validation accuracy.
- Hyper-parameters in Deep Q-learning are critical to ensure the training loop converges to the optimal solution. Moreover, complete reproducibility across platforms (e.g. Windows vs Mac), underlying hardware (GPU vs CPU), and PyTorch version is extremely hard, if not possible at the moment.
5. Homework 📚
👉🏽 notebooks/08_homework.ipynb
Let’s get your hands dirty:
- Git clone the repo to your local machine.
- Setup the environment for this lesson
03_cart_pole - Open
03_cart_pole/notebooks/08_homework.ipynband try completing the 2 challenges.
If you are not a deep learning master, I recommend you solve the 1st challenge. Increase the amount of train data and try to get to at least 95% accuracy in our imitation problem.
In the second challenge, I dare you to find a simpler neural network (e.g. with only 1 hidden layer) that can perfectly solve the CartPole problem.
6. What’s next? ❤️
In the next lesson, we are going to learn how to tune the hyper-parameters like a PRO, using the right tools for this.
Until then,
Love and learn.
And special thanks to Neria Uzan, for being so committed to the course. Thanks for the hard work and feedback you give me!

Do you want to become an (even) better data scientist, and access top courses about machine learning and data science?
👉🏽 Subscribe to the datamachines newsletter.