
Are you a data scientist using CSV files to store your data? What if I told you there is a better way? Have you ever heard of the Parquet file format?
Can you imagine a
- lighter 🦋
- faster 🏎️
- cheaper 💸
file format to save your datasets?
Read this article so you don’t need to imagine anymore
The problem
Do not get me wrong. I love CSVs.
You can open them with any text editor, inspect them and share them with others. They have become the standard file format for datasets in the AI/ML community.
However, they have a little problem…
CSV files are stored as a list of rows (aka row-oriented), which causes 2 problems:
- they are slow to query: SQL and CSV do not play well together.
- they are difficult to store efficiently: CSV files take a lot of disk space.
Is there an alternative to CSVs?
Yes!
Welcome Parquet file 🤗
As an alternative to the CSV row-oriented format, we have a column-oriented format: Parquet.
Parquet is an open-source format for storing data, licensed under Apache.
Data engineers are used to Parquet. But, sadly, data scientists are still lagging behind.
How is the Parquet format different from CSV?
Let’s imagine you have this dataset.
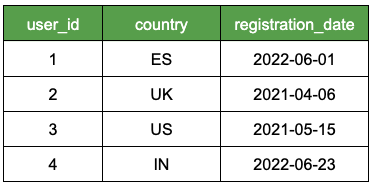
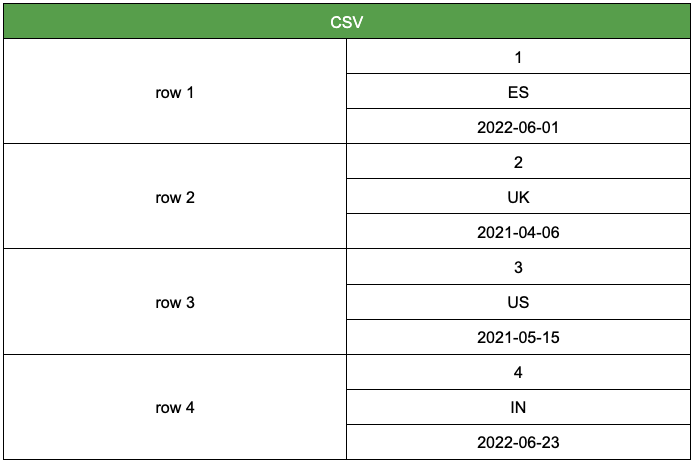
Internally, the CSV file stores the data based on its rows
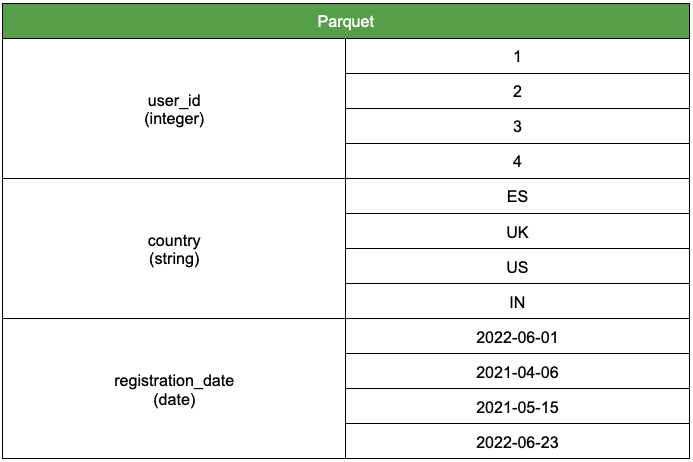
Parquet, on the other hand, stores the data based on its columns. It also saves the data type for each column, which is key to its success.
Why is column-storing better than row-storing?
2 technical reasons and 1 business reason.
- Tech reason #1. Parquet files are much smaller than CSV.
In Parquet, files are compressed column by column, based on their data type, e.g. integer, string, date. A CSV file of 1TB becomes a Parquet file of around 100GB (10% of the original size.
- Tech reason #2: Parquet files are much faster to query.
Columnar data can be scanned and extracted much faster.
For example, an SQL query that selects and aggregates a subset of columns does not need to scan the other columns. This reduces I/O and results in faster queries.
- Business reason #3: Parquet files are cheaper to store in Cloud services.
Storage services like AWS S3 or Google Cloud Storage charge you based on the data size or the amount of data scanned. Parquet files are lighter and faster to scan, which means you can store the same data at a fraction of the cost.
…and now the cherry on top of the cake
Working with Parquet files in Pandas is as easy as working with CSVs
Wanna read a Parquet file?
Stop doing:
pd.read_csv('file.csv')
instead, do
pd.read_parquet('file.parquet')
Wanna save data to disk as a Parquet file?
Stop doing:
df.to_csv('my_file.csv')
instead, do
df.to_parquet('my_file.parquet')
Wanna transform your old CSV file into a Parquet file?
Simple.
pd.read_csv('my_file.csv').to_parquet('my_file.parquet')
Let’s connect
If you want to learn more about real-world Machine Learning subscribe to my newsletter, and connect on Twitter and LinkedIn 👇🏽👇🏽👇🏽