
Even the most advanced AI models have their flaws
Would you say Deep Learning models have become so good, that robust AI systems are no longer a dream, but a reality?
Do you think you can safely use the latest models published by researchers in any real-world problem, like self-driving cars? Or face recognition software at airports?
Convinced that machines are already better than humans at processing and understanding images?
I was too. Until I realized it is possible to deceive a state-of-the-art model, like DeepMind Perceiver, with a few lines of code.
In this article, I will show you how you can do that in less than 10 minutes through a hands-on example. On the way, we will understand what are the implications of this example on real-world safe and robust AI.
All the code I show in this article is publicly available in this repo, and in this Colab notebook, you can run blazingly fast.
Let’s get into it!
The problem
Deep Learning models are highly flexible and powerful machines for capturing very complex patterns in the data.
They are the go-to solution for vision tasks (Computer Vision), textual tasks (Natural Language Processing), and real-world decision problems in robotics (Reinforcement Learning).
However, they are also very fragile to rare inputs.
A machine learning model works as expected when the input data you send to the model is similar to the one used to train the model.
When a model faces an input that is too different from the ones in the training set, the model can start to make silly mistakes.
You might be thinking…
This makes sense, but it does not apply to these massive Transformer based multi-billion parameter models, developed by DeepMind, OpenAI, Tesla, and other tech giants?
How can someone generate rare inputs, when these models were trained on tens (even hundreds) of million examples?
Well, it is ACTUALLY possible to fool these models too. And this is what I want to show you next.
Let’s see how you can generate a rare input that deceives DeepMind Perceiver, one of the latest and hottest DeepLearning models nowadays.
DeepMind Perceiver
DeepMind Perceiver was released in 2021. It’s a transformer-based model that can handle data from arbitrary settings, including images, videos, text, or audio.
This model is one solid step toward truly general architectures, as opposed to task-specific, that can process arbitrary sequences of inputs and outputs.
As you can imagine, this is not a toy model, but a truly powerful piece of engineering produced at DeepMind, one of the top AI labs in the world.
The exact version I will use in this example is the one publicly available at the HuggingFace model repository, which you can find here. It is a model with over 62M parameters, pre-trained on the ImageNet dataset, which contains over 14M images belonging to 20k categories.
3 steps to deceive DeepMind Perceiver
All the code I am showing in this section is in this notebook.
To keep things simple, we will start from the same example you can find in the HuggingFace model card, here.
where the image is this one:

As expected, the model correctly identifies this image as a cat.
>>> Predicted class: tabby, tabby catLet’s make slight adjustments to this image to fool the model and produce a so-called adversarial example. This adversarial example will look very similar to the original image but the model will have a hard time grasping it.
To generate an adversarial example from the original cat image we will use the Cleverhans library, and one of the simplest algorithms out there: the fast gradient sign method (aka FGSM), introduced by Goodfellow, Shlens, and Szegedy in this seminal paper.
If you wanna learn more about the FGSM and other adversarial example techniques, I recommend you read my previous article on adversarial examples 👇🏾
Step 1. Load model
First, we load the Perceiver model and preprocessor from the HuggingFace model hub.
>>> Number of parameters: 62,255,848
The function feature_extractor crops the input image to resolution 224×224 and normalizes the pixel values using mean and standard deviation. This kind of pre-processing is common practice for Deep Learning vision models.
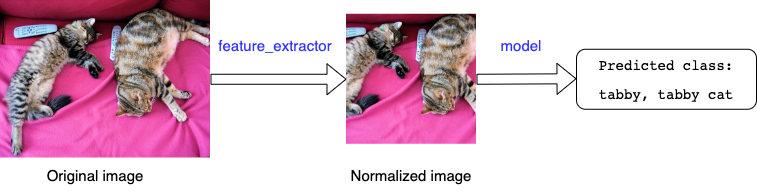
Step 2. Auxiliary function
I wrote an auxiliary function that reverses back this pre-processing and returns an image from a normalized tensor. I call this function inverse_feature_extractor
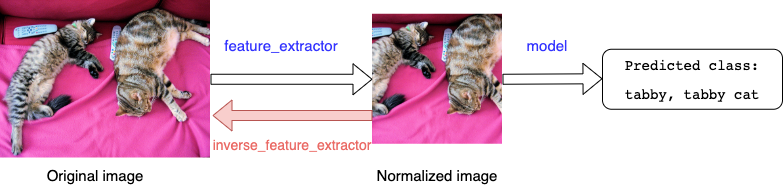
Step 3. Fast Gradient Sign Method attack
The next thing we do, we import Cleverhans’ fast_gradient_sign method. This function essentially takes 2 inputs, which are:
- the original image we want to modify → our beloved cats.
- epsilon, which is the size of the maximum distortion per pixel we allow →
eps. This value is always positive and small.
Once we set eps we run one fast_gradient_sign step and generate a new image from the original one. In general, you need to try different eps values and see which one works for the image you are using.
In this case, I literally spent 10 minutes to find that eps = 0.1 produces an adversarial example.
>>> Predicted class: English setter
(Image by the author)
English setter is a dog breed, by the way…
If you look closely at the image, you will notice it has a cloud of blue and green points on the cat on the left-hand side. Apart from this minor difference, the image is essentially the same as the original. However, the Perceiver fails to predict the correct class and thinks our cats are actually dogs. This is an adversarial example.

Implications for real-world safe and robust AI
In conclusion, deceiving models is way easier than training them. This is the asymmetry that exists between training and fooling (aka attacking) a deep learning model.
Hence, adversarial examples limit the applicability of deep learning models in the real world, and pose the following question:
Is it safe to use deep learning models, that can be easily fooled, in mission-critical tasks like self-driving cars, where human lives are at stake?”
There are ways to alleviate this problem, but they are not complete solutions, like adversarial training. However, the problem of defending against adversarial examples is far from being solved. Hence, robust AI is one of the key open problems in AI research.
We will not bridge the gap between research and robust AI by focusing on standard image classification datasets, like ImageNet.
Instead, we need to create algorithms to increase the robustness and interpretability of Deep Learning models.
You can find all the code in this repo.
Let’s connect
If you want to learn more about real-world Machine Learning subscribe to my newsletter, and connect on Twitter and LinkedIn 👇🏽👇🏽👇🏽