
Let’s build a Machine Learning service to predict the Air Quality Index (AQI) in your city in the next 3 days, using a 100% serverless stack.
You will learn a lot, AND you will build something useful for society. Win-win
These are steps to build this ↓
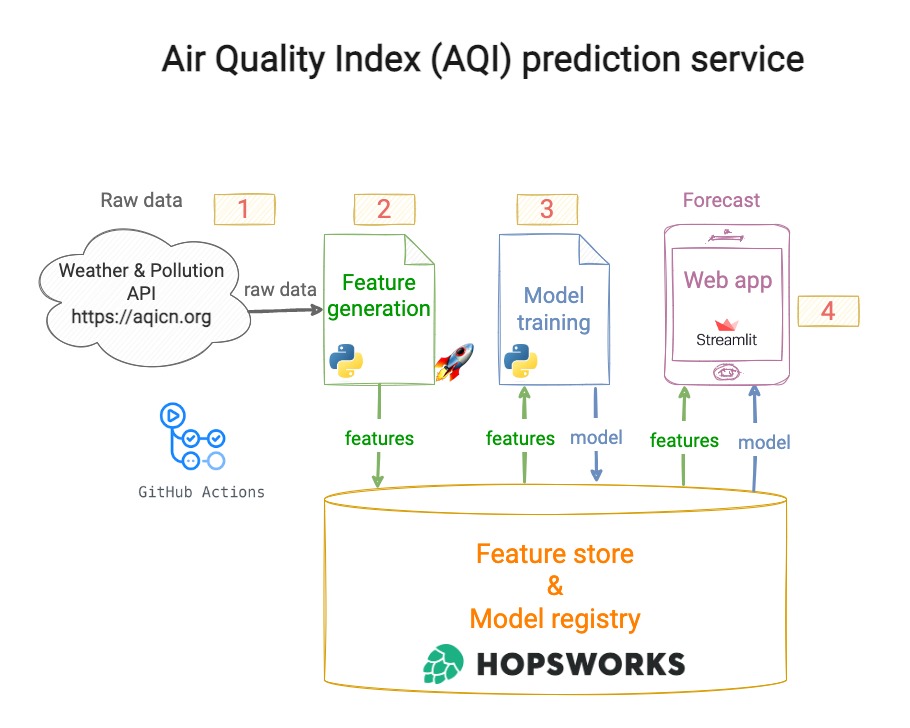
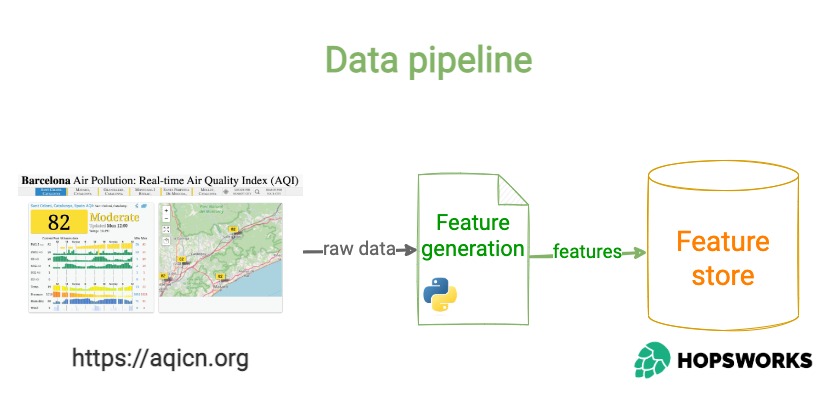
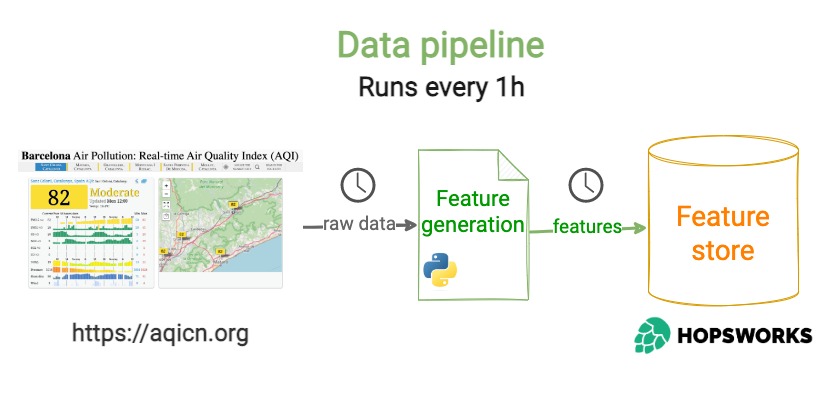
Step 1 – Feature generation script
1 → fetches raw weather and pollutant data from an external API like https://aqicn.org
2 → computes features from this raw data (aka model inputs), and targets (aka model outputs)
3 → stores these features in the *Feature Store*
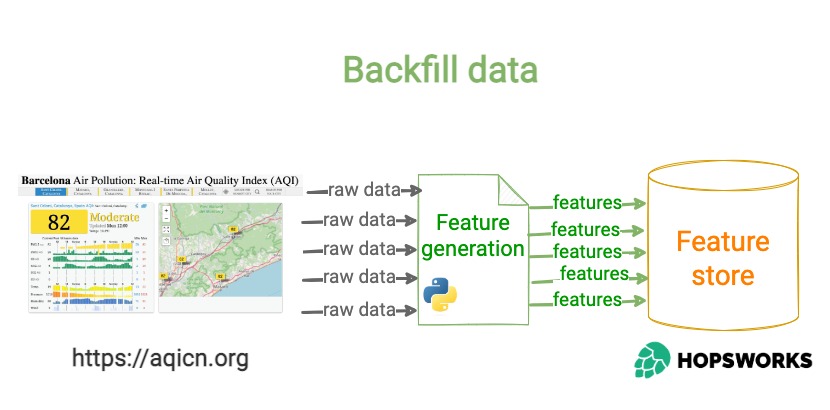
Step 2 – Backfill historical (features, targets)
To train a Machine Learning model later, you need enough historical data (features, targets) in your Feature Store. Run the feature script for a range of past dates, to get enough training data.
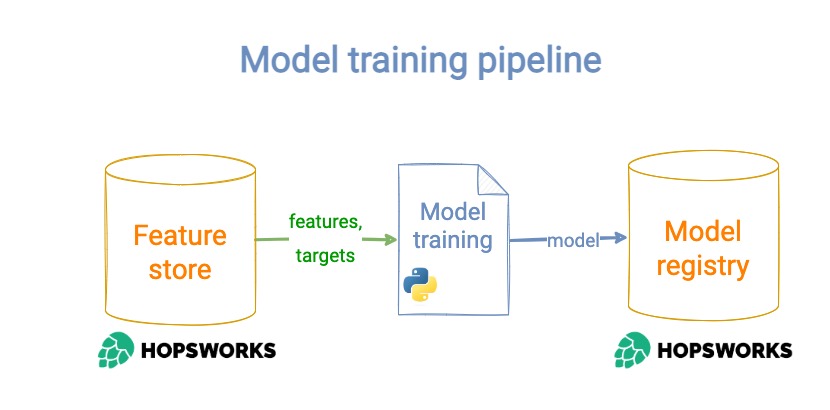
Step 3 – Model training script
1 → fetches historical (features, targets) from the Feature Store.
2 → trains and evaluates the best ML model possible for this data, e.g. XGBoostRegressor.
3 → stores the trained model in the Model Registry.
Step 4 – Automate execution of the feature script
Create a GitHub action to automatically run the feature script (from step 1) every hour.
GitHub actions are serverless computing power to run your code on a schedule. For free. Beautiful.
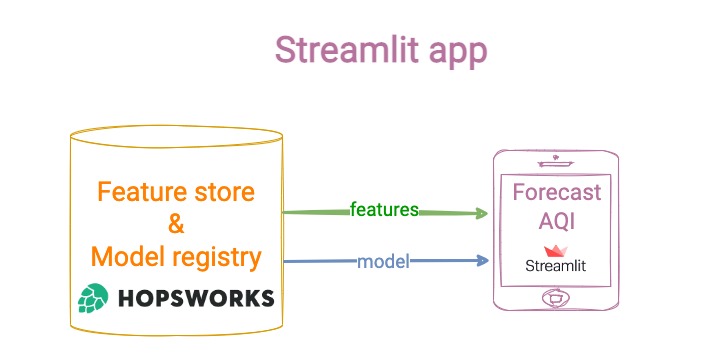
Step 6: Create a web app to show model predictions
Streamlit is a powerful Python library to develop and deploy web data apps.
Your app
1 → loads the model and features from the *Feature Store*
2 → computes model predictions and shows them on a beautiful UI.
BOOM!
Bonus
You can create another GitHub action to automate the model training script.
Why re-train the model?
Because ML model performance decreases over time. The best way to mitigate this is to regularly re-train the model, like once a week.
Wanna learn to design, develop and deploy a real-world ML system yourself?
Join the Real-World ML Tutorial + Community and get LIFETIME ACCESS to
→ 3 hours of video lectures 🎬
→ Full source code implementation 👨💻
→ Discord private community, to connect with 100+ students and me 👨👩👦

Wanna design, develop and deploy real-world ML products?
Join 7.5k Machine Learning developers in our weekly newsletter.
Read The Real World ML Newsletter every Saturday morning.
Drop your email below to subscribe ↓