
Reading blog posts about multi-billion-parameter Language Models is very cool. However, building real-world NLP products from these models is where the real business value is. And this is what companies look for in the job market.
So, here is a PRO project you can build.
“An app that recommends what ML paper to read”
Imagine an app where you can describe what paper you are interested in reading today. For example
“I want a paper about Transformers in Computer Vision”
Stop imagining. Instead, build this system ↓ in 4 steps
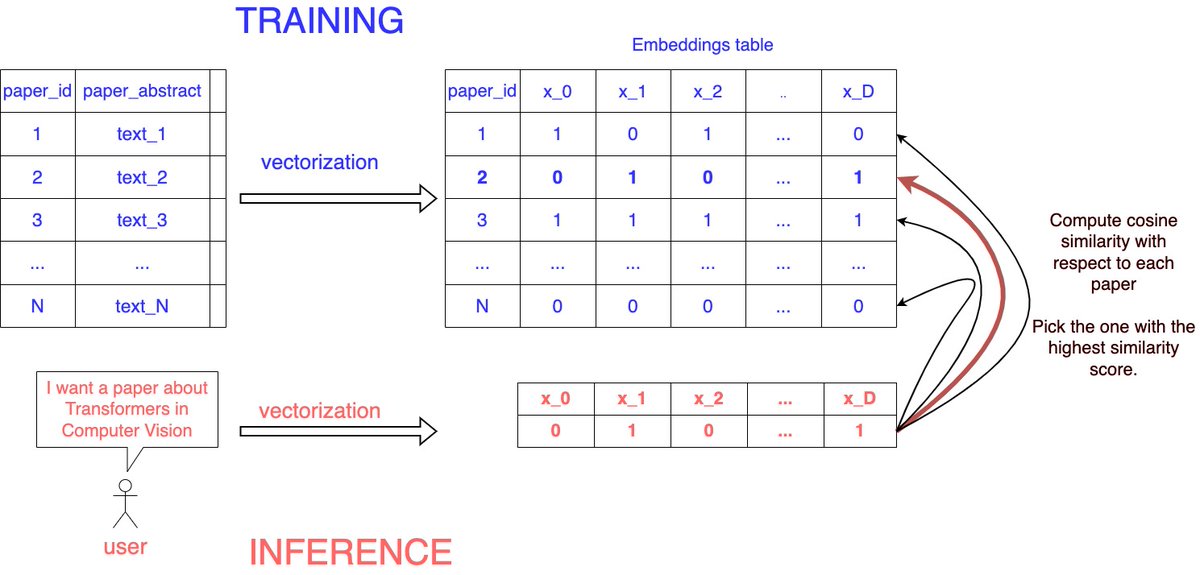
Step 1: Gather data about arXiv papers and their abstracts
You can use a dataset like this.
Step 2: Compute text embeddings
Text embedding is THE most useful technique ever invented in NLP.
You have several options to embed/vectorize your text:
- TF-IDF vectorizer from scikit-learn (classic)
- GloVe word embeddings (modern)
- Sentence Transformers using HuggingFace’s library (SOTA)
Step 3: Implement a scoring function
Which takes as input the text query from the user
“I want a paper about Transformers in Computer Vision”
vectorizes it, and finds the paper in your data with the highest similarity score, using, for example, cosine similarity.
Step 4: Build a public web app
You need to put the app in front of people’s eyes.
For that, Streamlit Cloud is a powerful and FREE option you can use.
BOOM!
Wanna build this system?
In The Real-World ML Tutorial, you will learn how to build *complete* end-2-end ML services that solve business problems.
➡️ Click here to read all the details
Subscribe to my e-mail list to level up in Data Science, Machine Learning and MLOps ↓