
Real-time ML is a fascinating topic, which I wanna go deeper into in the following weeks and months. Because of this, I started creating a sequence of small projects where I build real-time products, beginning with a real-time feature engineering pipeline.
Real-time feature engineering
A real-time feature pipeline is a program that
- ingests real-time raw data (e.g. from an external web socket, or from an enterprise message bus like Kafka),
- processes this raw data into features (aka inputs for your ML model), and
- sends these features to downstream services (e.g. a Feature Store, or back to the message bus).
Traditionally, real-time feature engineering has been a rather obscure topic among data scientists and ML engineers. The reason is that Python, the lingua franca in the ML world, is not suitable for stream processing, due to its slowness. Hence, traditional stream processing engines and tools have been written in more efficient languages, like Java, which lay outside the core skills of most ML engineers. Data engineers, who often have a software engineering background, have taken the responsibility to implement and manage real-time pipelines using Java-based tools like Apache Spark or Apache Flink.
Luckily things have changed with the emergence of Rust, a next-generation compiled language, which binds very naturally with Python interfaces. Bytewax, a Python library with native Rust bindings, is a great example of this.
Bytewax is the library that I decided to use for this little project. Let’s see how it works and how I used it to build my MVP.
From raw trades to OHLC data
You can find all the code in this GitHub repo, and the final app is publicly deployed on Streamlit Cloud 👉🏽 click here to see it in action
Bytewax is designed following a dataflow paradigm. The dataflow is the sequence of operations and transformations necessary to
- ingest incoming data → e.g. read real-time data from a Coinbase websocket,
- transform it sequentially, using either
- stateless transformations → e.g. parse strings to Python dictionaries.
- stateful transformations → e.g. aggregate trade prices over 30-second windows, and
- output the final data to an output sink → e.g. plot the final OHLC data on a Streamlit/Bokeh UI component.
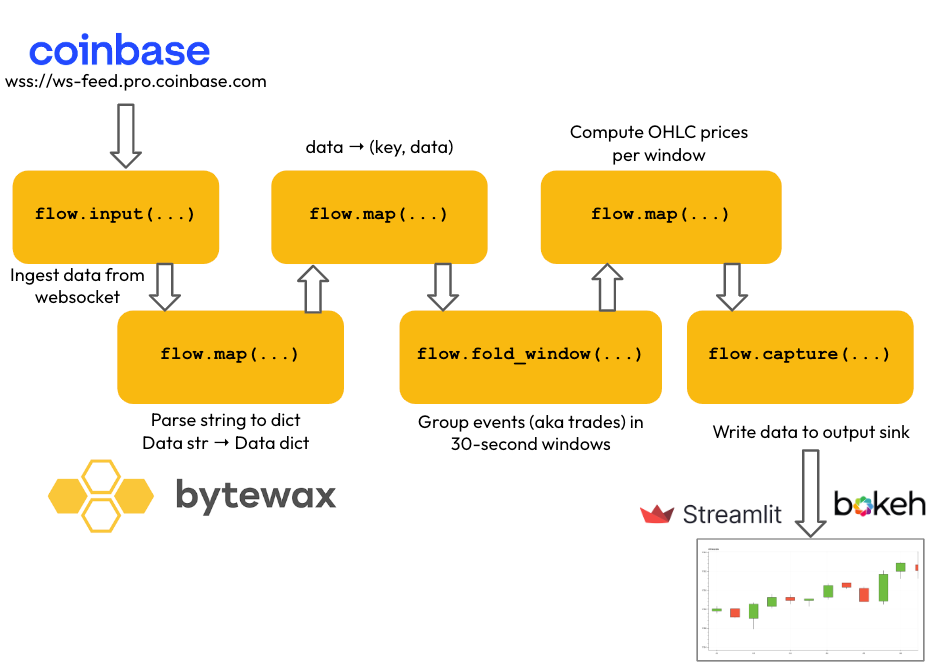
To execute a dataflow, you first need to create it and then attach each of the steps, including input fetching and output writing. Only then you can run it.
Each data flow step is defined by
- an operation primitive, for example
map(…)is a 1-to-1 mapping, and - a custom function (e.g.
json.loads) that specifies what this 1-to-1 mapping does (in this case parse a string into a Python dictionary).
💡 Tip
Writing stream processing pipelines in Bytewax is all about understanding what are the primitives to choose and the custom functions to implement to build each of the dataflow steps.
In my code, I split the dataflow construction into 2 files:
src/dataflow.py→ defines the dataflow from input to the penultimate step.src/frontend.py→ adds the last step to the dataflow, to plot the data on a Streamlit/Bokeh char.
If you are interested and wanna dig deeper into the implementation details, I recommend you take a look at the GitHub repo. And give it a ⭐ if you found it useful.
Next steps
The app I just described is a good first project. However, it lacks one crucial ingredient, and that is data persistence. Every time you re-load the frontend app, you lose all the historical OHLC data processed until then.
To solve that, I am planning to add a Feature Store, where we can store (and later serve) the OHLC data generated by the feature pipeline.
Wanna design, develop and deploy real-world ML products?
Join 7.5k Machine Learning developers in our weekly newsletter.
Read The Real World ML Newsletter every Saturday morning.
Drop your email below to subscribe ↓
Keep on learning!
Pau