Training Machine Learning models inside notebooks is just one step to building real-world ML services. And as exciting as it is, it brings no business value unless you deploy and operationalize the model, as a real-world ML app.
In this article, you will learn how to transform an all-in-one Jupyter notebook with data preparation and ML model training, into a fully working batch-scoring system using a serverless ML stack.
For that, we will follow the 3-pipeline design.
Let’s get started!
The starting point
The starting point is this one Jupyter notebook where you:
- Loaded data from a CSV file
- Engineered features and targets
- Trained and validated an ML model.
- Generated predictions on the test set.
Let’s turn this notebook into a real-world ML app for batch prediction.
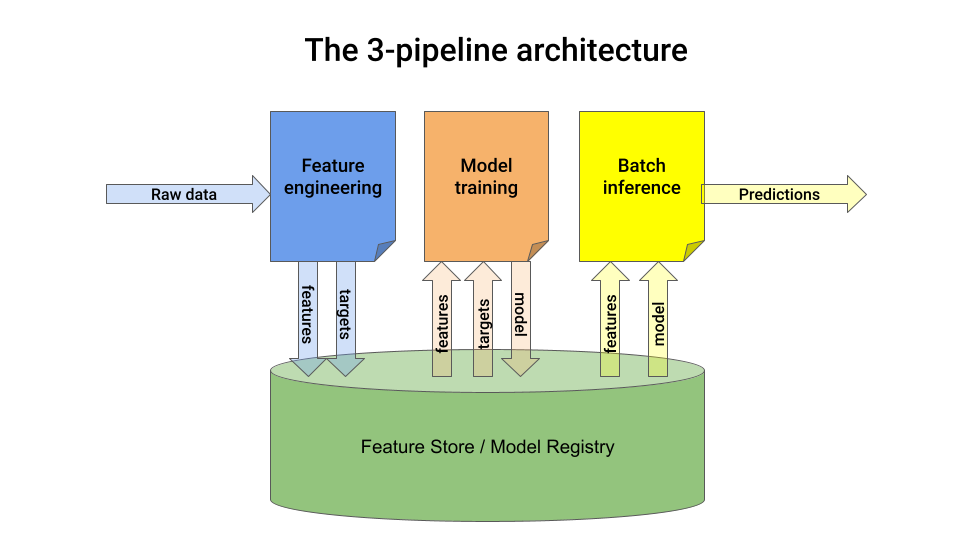
The 3-pipeline architecture
A batch-prediction service ingests raw data and outputs model predictions on a schedule (e.g. every 1 hour).
You can build one using this 3-pipeline architecture
Step 1. Build the feature pipeline
Break your initial all-in-one notebook into 2 smaller ones:
- Notebook A , reads raw data and generates features and targets.
- Notebook B, takes in features and outputs a trained model.
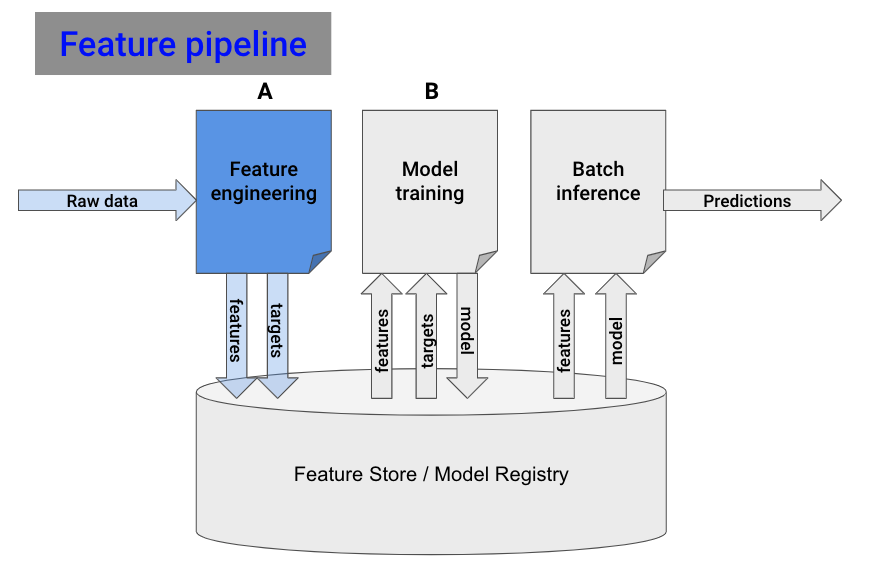
Notebook A is your feature pipeline. Let’s put it now to work.
You need 2 things:
- Automation. You want the feature pipeline to run every hour. You can do this with a GitHub action.
- Persistence. You need a place to store the features generated by the script. For that, use a managed Feature Store.
Step 2. Model training pipeline
Remember the 2 sub-notebooks (A and B) you created in step #1?
Notebook B is your model training pipeline.
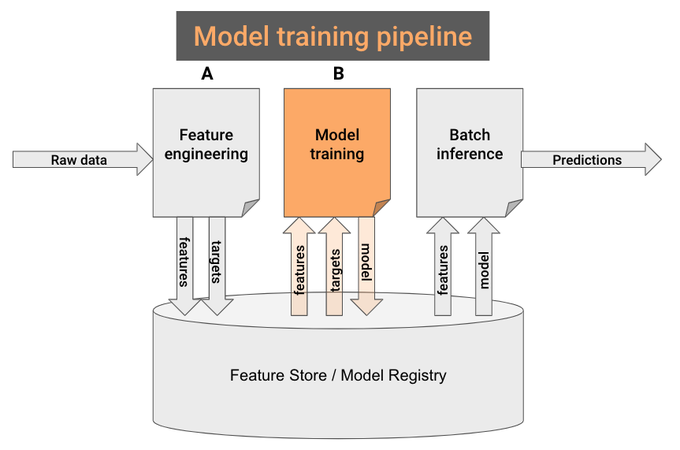
Well, almost. You only need to change 2 things…
- Read the features from the Feature Store, and not CSV files.
- Save the trained model (e.g. pickle) in the model registry, not locally on disk, so the batch-inference pipeline can later use it to generate predictions.
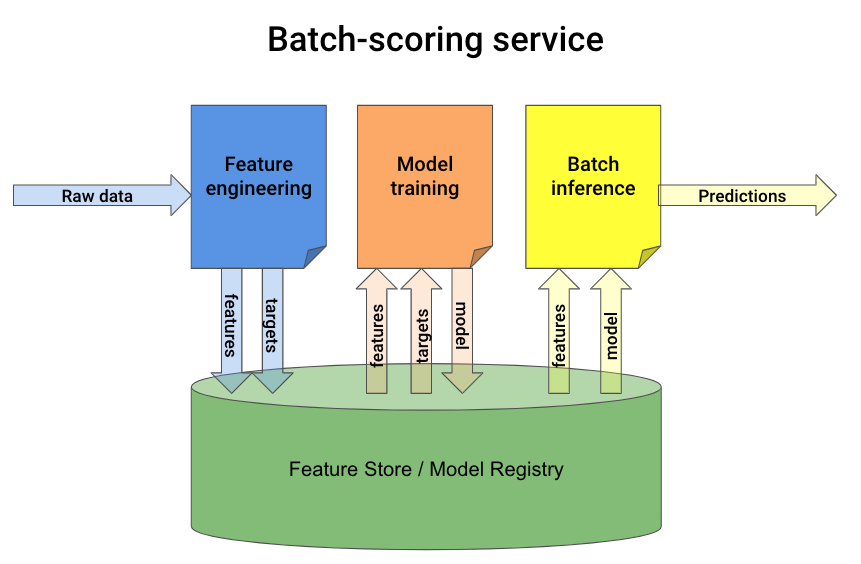
Step 3. Build the batch-prediction pipeline
Build a new notebook that:
- Loads the model from the model registry
- Loads the most recent feature batch.
- Generates model predictions and saves them somewhere (e.g. S3, database…) where downstream services can use them.
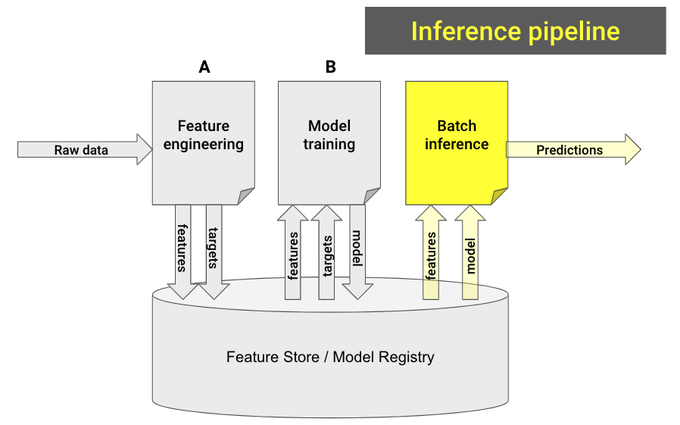
Finally, you create another GitHub action to run the batch-inference pipeline on a schedule.
Boom.
Wanna learn to design, develop and deploy a real-world ML system yourself?
Join the Real-World ML Tutorial + Community and get LIFETIME ACCESS to
→ 3 hours of video lectures 🎬
→ Full source code implementation 👨💻
→ Discord private community, to connect with 100+ students and me 👨👩👦
