Imagine you work as an ML engineer at a Fintech startup, and you are tasked to build a new credit card fraud detection system.
Imagine you have already
- defined the problem with relevant stakeholders
- built a training dataset
- trained a good model to detect fraud (for example, a binary classifier) inside a notebook
- created a REST API around your model using Flask or FastAPI, and
- committed all the code to a private GitHub repository.
It is time to put the model to work for the company. And that means, you need to deploy it.
But how do you do that? 🤔
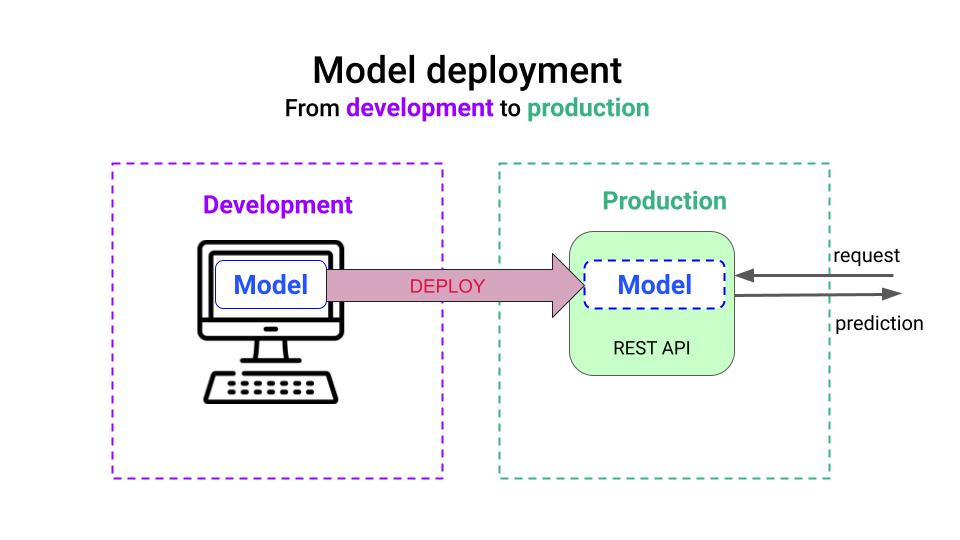
Attempt 1. Ask the DevOps engineer to do it for you 👷
The simplest way to deploy the model would be to
- Push all the Python code and the serialized model (pickle) to the GitHub repository, and
- Ask the DevOps in the team guy to wrap it with docker and deploy it to the same infrastructure used for the other microservices, for example
- a Kubernetes cluster, or
- an AWS Lambda function, among others.
This approach is simple, but it has a problem.
❌ ML models need to be frequently re-trained to adjust them to changes in the underlying patterns in the data. Hence, you would need to often bother the DevOps guy to re-trigger the deployment manually, every time you have a new version of the model.
Fortunately, there is a well-known solution for this, called Continuous Deployment (CD).
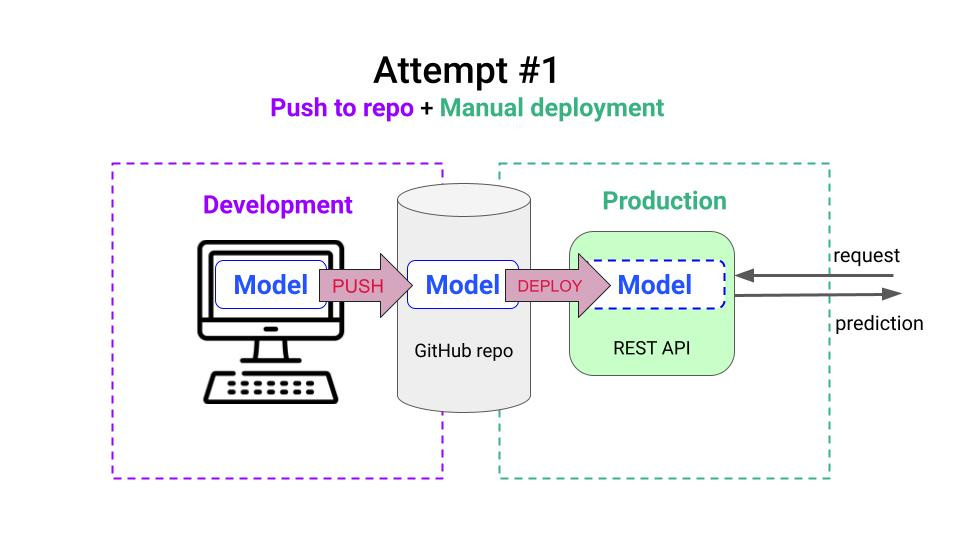
Attempt 2. Automate with Continuous Deployment 🤖
DevOps guys are experts at automating things, including deployments.
In this case, your DevOps guy creates a GitHub action that is automatically triggered every time you push a new version of the model to the GitHub repo, that dockerizes and pushes the code to the inference platform (e.g. Kubernetes, AWS Lambda, etc).
Voila. Automation to the rescue!
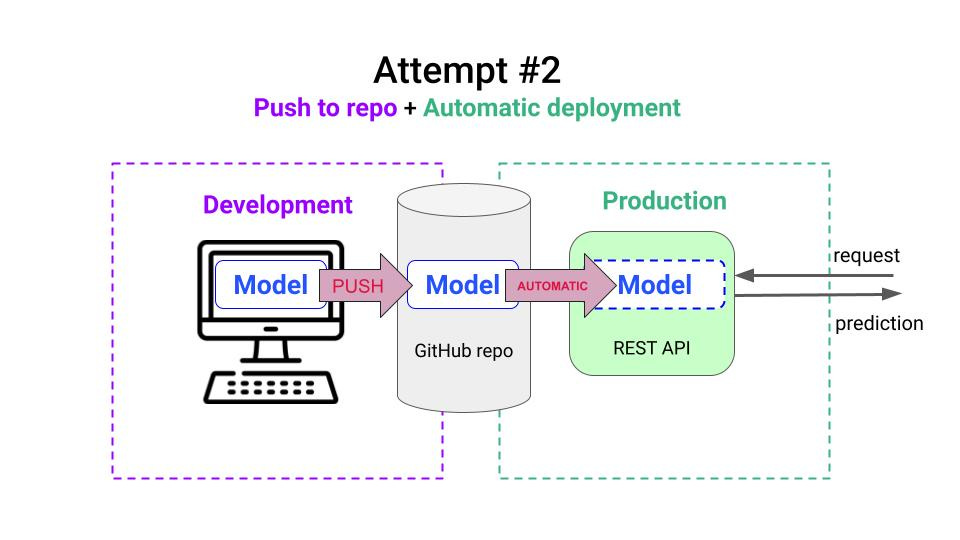
You and your DevOps guy are happy with the solution… until one day your model breaks… and the company loses a hefty amount of money from fraudulent transactions.
Friendly reminder 🔔
In Machine Learning, like in Software Engineering, things are doomed to break at some point.
And in ML they break often.. usually because of problems in the underlying data used to train the model.
So the question is
Is there a way to control model quality before deployment, and easily decide which model (if any) should be pushed to production?
And the answer is YES!
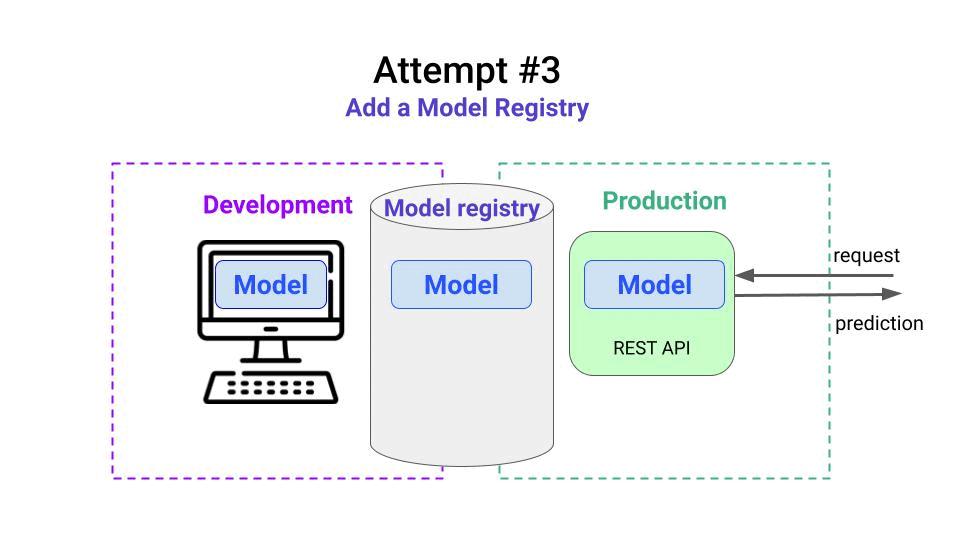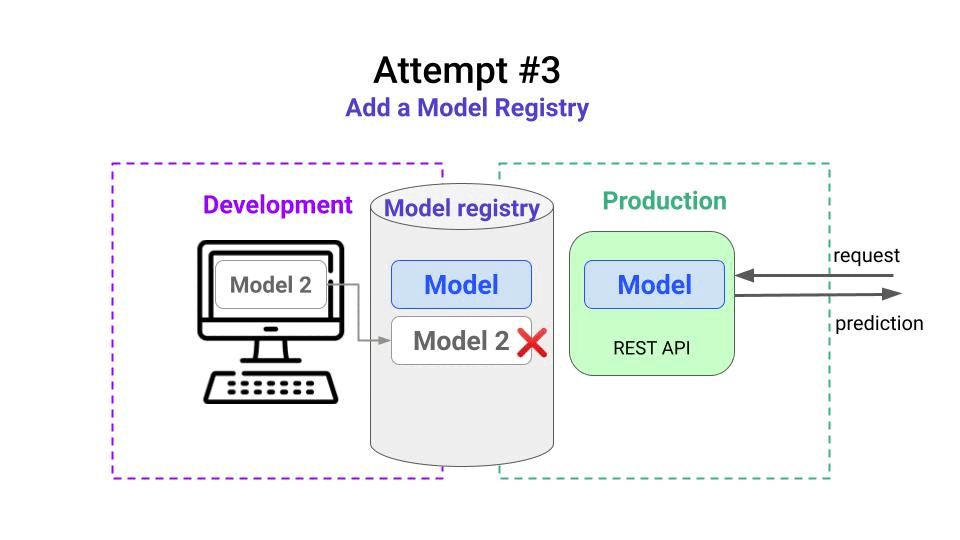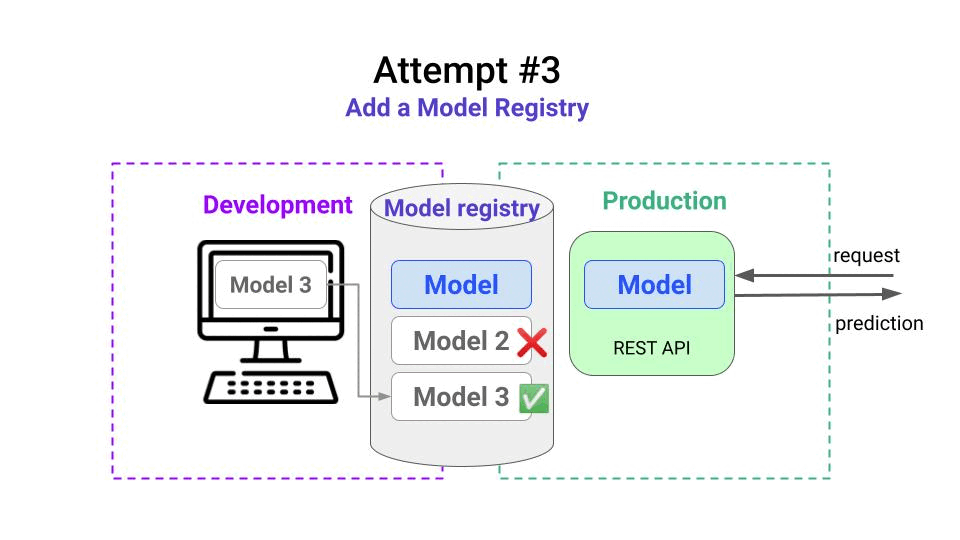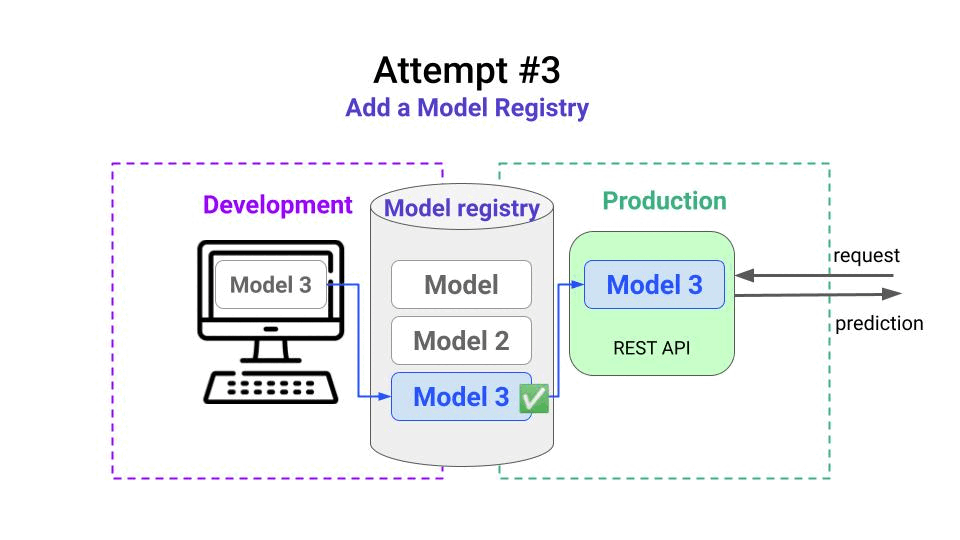
Attempt 3. Hello, Model Registry 👋🏽
The Model Registry is the MLOps service where you push every trained ML mode so you can
- access the entire model lineage (aka what exact dataset, code, and parameters generated each model)
- compare models easily
- promote models to production, when they meet all the quality requirements, and
- automatically trigger deployments via webhooks.
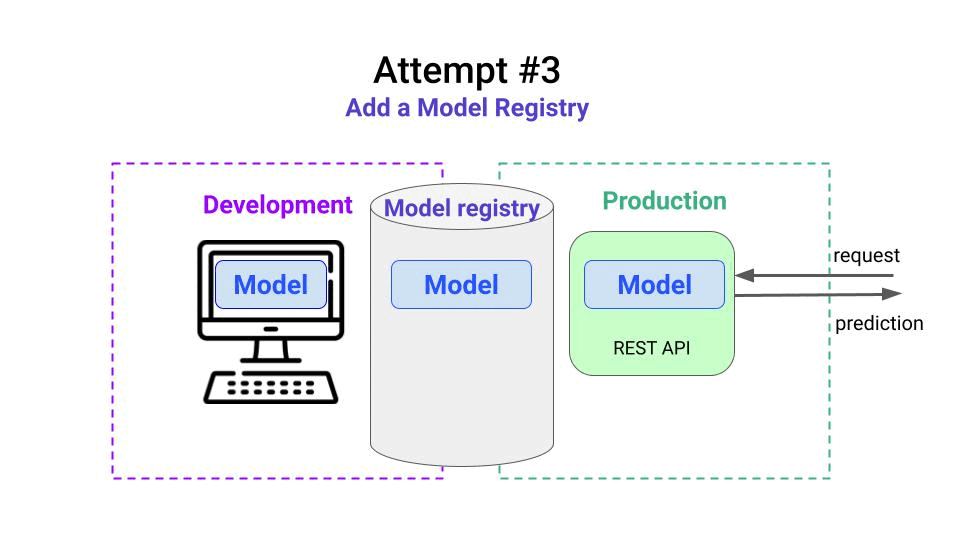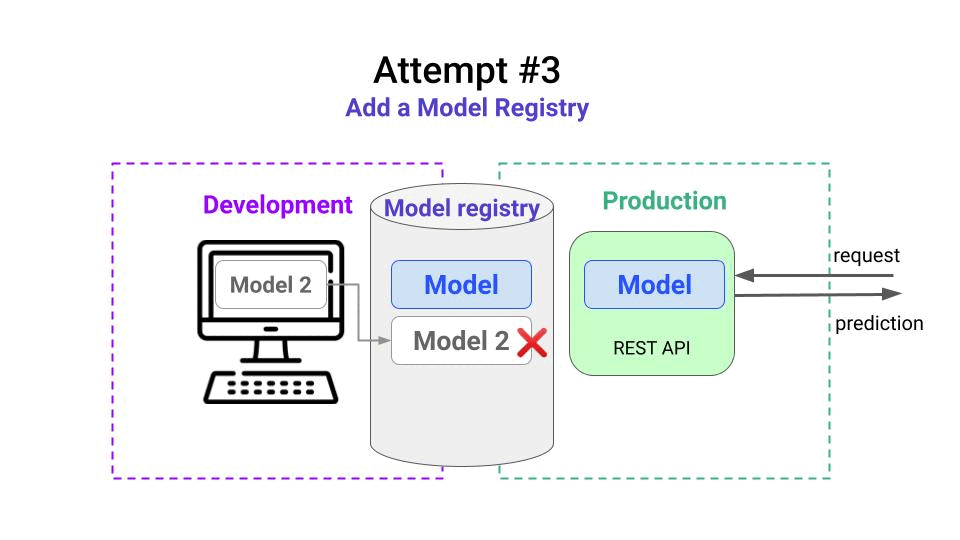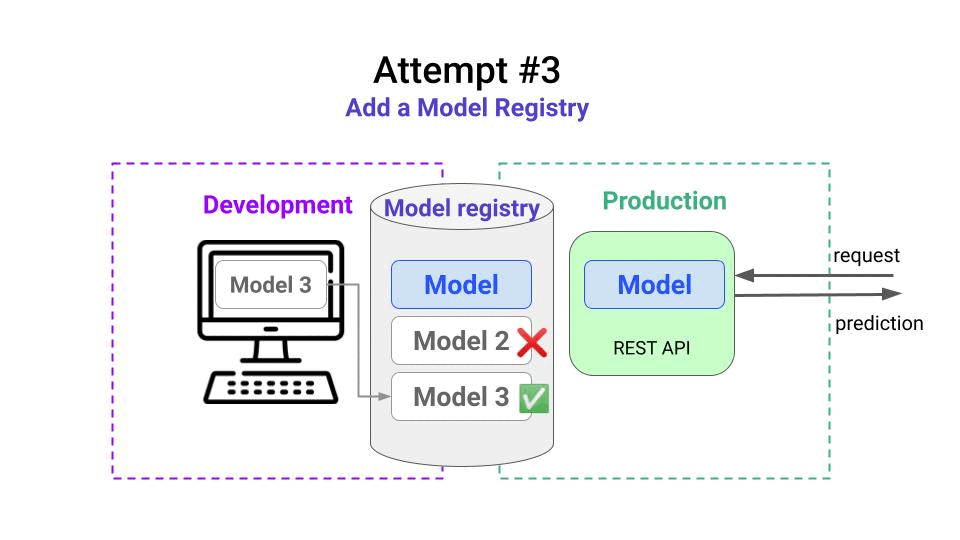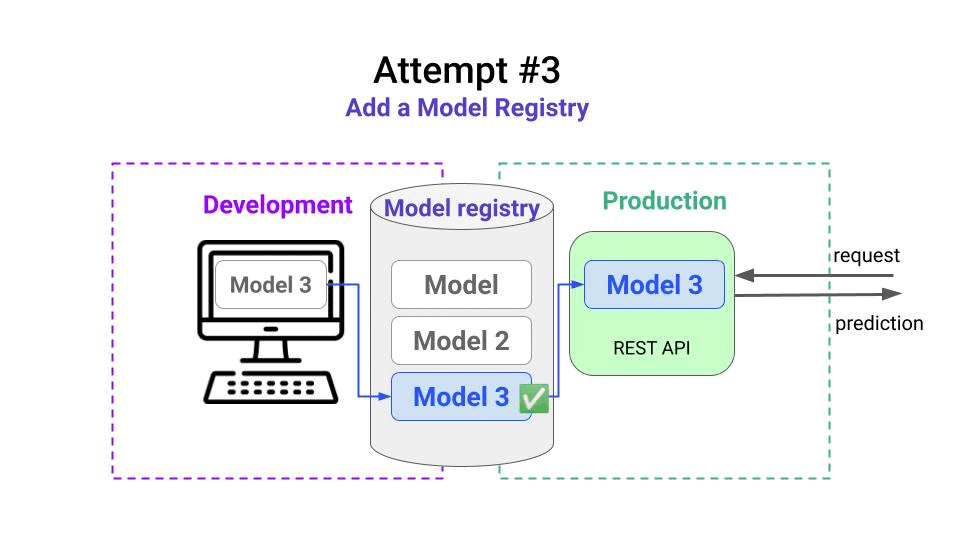
In this example, your first Model is running in production, but your monitoring system is telling you to re-train it. So you go back to your laptop and follow these steps:
- train a new model called Model 2
- push it to the registry.
- compare its performance with the one in production. You can even invite a senior colleague to perform this validation step.
- realize the new model you trained is worse than the production model, so you decide not to promote it. ❌
- check the model lineage, and realize the input data used to train the model was full of missing values.
- ask the data engineer guy to fix the data problem upstream,
- re-train the model to create Model 3
- compare Model 3 with the production model, and realize the new model is better. ✅
- deploy Model 3 with the webhook trigger. 🚀
In the real world, having this model management flow ensures the company doesn’t lose money… and your career flourishes.
My advice 🧠
I strongly recommend you add a Model Registry to your ML toolset, as it brings reliability and trust to the ML system and enhances collaboration between team members.
Tip 💡
The Model Registry and Experiment Tracker tool I use is Comet ML because it is
- Serverless, which means you do not need to take care of extra infrastructure. All you need is an API key 🔑
- Includes top-notch features like full model lineage and webhooks 🪝
- FREE for individuals like you and me 👌
→ Sign up for FREE today and start building your next MLOps project.
Wanna design, develop and deploy real-world ML products?
Join 8.5k Machine Learning developers in our weekly newsletter.
Read The Real World ML Newsletter every Saturday morning.
Drop your email below to subscribe ↓
Keep on learning!
Pau