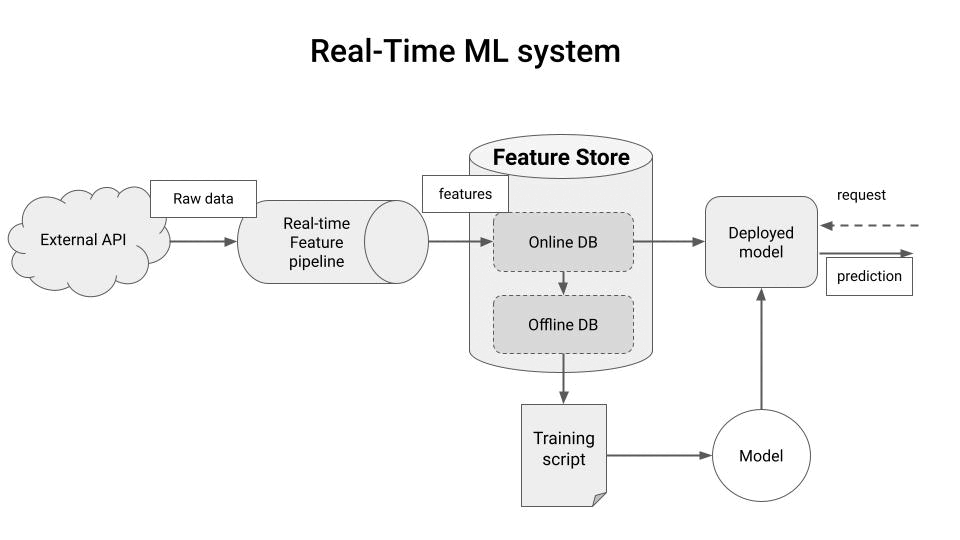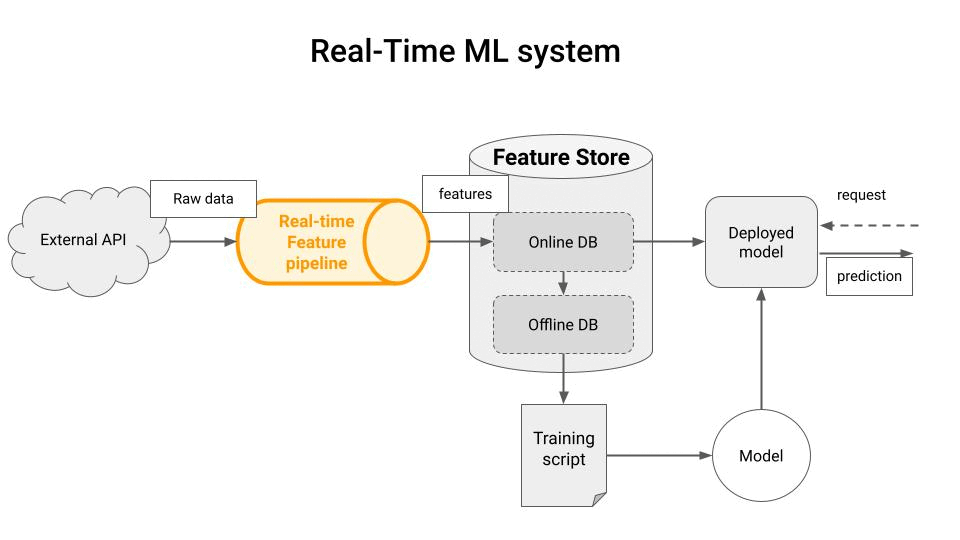
Machine Learning models are as good as the input features you feed at training and inference time.
And for many real-world applications, like financial trading, these features must be generated and served as fast as possible, so the ML system produces the best predictions possible.
Generating and serving features fast is what a real-time feature pipeline does.
Can I build real-time feature pipelines in Python?
YES!
Python alone is not a language designed for speed 🐢, which makes it unsuitable for real-time processing. Because of this, real-time feature pipelines were usually written with Java-based tools like Apache Spark or Apache Flink.
However, things are changing fast with the emergence of Rust 🦀 and libraries like Bytewax 🐝 that expose a pure Python API on top of a highly-efficient language like Rust.
So you get the best of both worlds.
- Rust’s speed and performance, plus
- Python’s rich ecosystem of libraries.
So you can develop highly performant and scalable real-time pipelines, leveraging top-notch Python libraries.
🦀 + 🐝 + 🐍 = ⚡
Example: Real-time feature pipeline for crypto trading
You can find all the code in this repository. Give it a star ⭐ on GitHub if you find it useful
Bytewax is designed following a dataflow paradigm. The dataflow is the sequence of operations and transformations necessary to
- ingest incoming data → e.g. read real-time data from a Coinbase websocket,
- transform it sequentially, using either
- stateless transformations → e.g. parse strings to Python dictionaries.
- stateful transformations → e.g. aggregate trade prices over 30-second windows, and
- output the final data to an output sink → e.g. plot the final OHLC data on a Streamlit/Bokeh UI component.

To execute a dataflow, you first need to create it and then attach each of the steps, including input fetching and output writing. Only then you can run it.
# instantiate dataflow object
from bytewax.dataflow import Dataflow
flow = Dataflow()
# read input data from websocket
flow.input("input", ManualInputConfig(input_builder))
# parse string data to Python dictionaries
# 1-to-1 stateless operation
flow.map(json.loads)
# generate a key to index the data (key, data)
# this is a preliminary step to use a stateful operator (see next step)
# 1-to-1 stateless operation
flow.map(key_on_product)
# aggregate events (aka trades) in 30-second windows
# Stateful operation
flow.fold_window("30_sec", cc, wc, build_array, acc_values)
# compute Open-High-Low-Close prices for each window
flow.map(calculate_features)
# send output to the Feature Store
flow.capture(ManualOutputConfig(output_builder))
# time to run it!
from bytewax.execution import run_main
run_main(flow)Each data flow step is defined by
- an operation primitive, for example
map(…)is a 1-to-1 mapping, and - a custom function (e.g.
json.loads) that specifies what this 1-to-1 mapping does (in this case parse a string into a Python dictionary).
💡 Tip
Writing stream processing pipelines in Bytewax is all about understanding what are the primitives to choose and the custom functions to implement to build each of the dataflow steps.
Github repo
In this repository, you will learn how to develop and deploy a real-time feature pipeline with Bytewax that
- fetches real-time trade data (aka raw data) from the Coinbase Websocket API
- transforms trade data into OHLC data (aka features) in real-time using Bytewax, and
- stores these features in the Hopsworks Feature Store
You will also build a dashboard using Bokeh and Streamlit to visualize the final features, in real-time.
I would be also very grateful if you could give a star ⭐ to the GitHub repository if you like it 🙏.
Let’s go real time! ⚡
The only way to learn real-time ML is to get your hands dirty.
→ Go pip install bytewax
→ Support their open-source project and give them a star on GitHub ⭐ and
→ Start building 🛠️
Wanna design, develop and deploy real-world ML products?
Join 8.5k Machine Learning developers in our weekly newsletter.
Read The Real World ML Newsletter every Saturday morning.
Drop your email below to subscribe ↓
Keep on learning!
Pau